Operating Systems
Datacenter Technologies
11 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Datacenter Technologies
Internet Services
An internet service is any type of service that is accessible via a web interface.
Users communicate with these services via web requests that are issued by their web browsers.
Most commonly, these services are divided into three tiers. The presentation tier is typically responsible for static content related to the webpage layout. The business logic tier integrates all of the business-specific processing, including all of the dynamic, user-specific content. The database tier deals with all of the data storage and management.
These different tiers do not need to run as separate processes on separate machines. For example, the Apache HTTP web server can fulfill the presentation tier and the business logic tier.
Many middleware components exists to connect and coordinate these tiers.
Multiprocess configurations will need to communicate via some form of IPC, which we have discussed previously.
Internet Service Architectures
For services that need to deal with high or variable requests rates, choosing a configuration that requires multiple processes - potentially on multiple nodes - becomes necessary.
We can scale out a service deployment by running the service on more nodes.
A front-end load-balancing component would route the incoming request to an appropriate or available machine that implements the internet service.
Behind the load balancer, we can have one or two different setups. In a homogenous setup, all nodes are able to execute any possible step in the request processing pipeline, for any request that can come in. In a heterogenous setup, nodes execute some specific steps in the request processing, for only some request types.
Homogenous Architectures
Any node in a functionally homogenous setup can process any type of request and can perform any of the processing actions that is required in the end-to-end request processing.
The benefit of this is that the front-end (load balancer) can be kept very simple. It doesn't have to keep track of which node can service which type of request; instead, it can assign requests in a round-robin manner to the next available node.
This design doesn't mean that every node has all of the data. Instead, data may somehow be replicated or distributed across the nodes. Importantly, every node is able to get to any type of information that is necessary for the execution of the service.
One downside of this approach is that there is little opportunity to benefit from caching. A simple front-end will not keep enough to understand the locality of each task on a node by node basis.
Heterogenous Architectures
In a functionality heterogenous setup, different nodes are designated to perform certain functions or handle certain types of requests.
For instance, requests may be divided among the servers based on request content. In the case of eBay, servers may be specialized for browsing requests vs. bidding/buying requests.
Since different nodes perform different tasks, it may not be necessary to ensure that data is uniformly accessible everywhere. Certain types of data may be much more easily accessible from the servers that manipulate those types of data.
One benefit of this approach is that the system can benefit from caching and locality, as each node is specialized to repeatedly perform one or a few actions.
One downside of this approach is that the front-end needs to be more complex. The front-end now needs to perform some request parsing to determine to which node it should route the request.
In addition, the overall management of this system becomes more complex. When a machine fails, or requests increases, it is important to understand which types of servers need to be scaled out.
Also, if something changes fundamentally in the workload pattern, the server layout needs to be reconfigured. It's not as easy as scaling up or down.
Cloud Computing Poster Child: Animoto
Amazon was a dominant online retailer in the early 2000s. However, the workload that they needed to handle was imbalanced. The bulk of their traffic was received during the holiday shopping season, and much of the hardware they provisioned sat idle outside of that window.
In 2006, Amazon opened up access to its hardware resources via web-based APIs. This meant that third party workloads could be run on Amazon resources, for a fee.
This was the birth of Amazon Web Services (AWS) and Amazon Elastic Cloud Compute (EC2).
Around the same time, a company called Animoto was created. This company stitched together photos into a movie, which is a fairly resource-intensive task. As a result, they chose to rent EC2 instances instead of building out their own datacenter.
Originally, Animoto required about 50 EC2 instances.
In 2008, Animoto became available to Facebook users. Within three days, Animoto signed up 750,000 new users, and scaled up to 3,400 EC2 instances.
In a week, Animoto had scaled up the number of servers it used by two orders of magnitude.
There's no way they would have been able to respond to this demand if they had gone the traditional route of owning and managing their own infrastructure.
Cloud Computing Requirements
Traditionally, business would need to buy and configure the resources that were needed for their services. The number of resources to buy/configure would be based on the peak expected demand for those services.
If the demand exceeded the expected capacity, the business would into a situation where requests have to be dropped, which would result in lost opportunity.
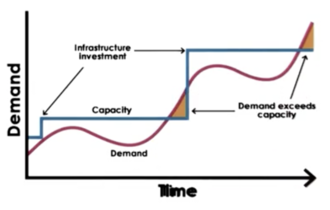
Ideally, we would like the capacity of the available resources to scale elastically with the demand.
The scaling should be instantaneous: as soon as the demand increases, so does the capacity, and vice versa. This means that the cost to support this service should be directly proportional to the demand.
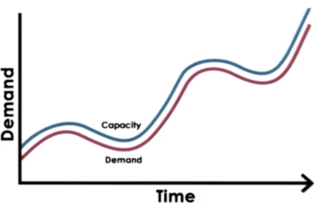
All of this scaling should be able to happen automatically, and the provisioned resources should be accessible anywhere, anytime.
Note that you wouldn't potentially own these resources, but this may be a fair compromise.
Goals of cloud computing, summarized:
- On-demand, elastic resources and services
- Fine-grained pricing based on usage
- Professionally managed and hosted
- API-based access
Cloud Computing Overview
Cloud computing provides shared resources. These resources can be infrastructure resources; that is, compute, storage or networking resources. Cloud computing can also provide higher-level software resources, like email or database services.
These infrastructural/software resources are made available via some APIs for access and configuration. These resources need to be accessed and manipulated as necessary over the Internet. APIs can be web-based, library-based, or command line-based.
Providers offer different types of billing and accounting services. Some marketplaces incorporate spot pricing, reservation pricing, or other pricing models.
Billing is often not done by raw usage, as overheads with monitoring at that level of fine-grained control are pretty high. Instead, billing is done based on some discrete step function. For example, compute resources may be billed according to "size": tiny, medium, extra-large.
All of this is managed by the cloud provider. Common software stacks more managing cloud resources include the open source OpenStack and VMware's vSphere software stack.
Why Does Cloud Computing Work?
Two basic principles provide the fundamental theory behind the cloud computing approach.
The first is the law of large numbers. This says that average resource needs across a large number of clients will remain fairly constant. This is the reason that a cloud provider can support a number of clients with variable peak loads on a fixed amount of resources.
The second is economies of scale. A cloud provider is able to leverage a large number of customers on a single piece of hardware, which amortizes the cost of that hardware across those customers, assuming the number of customers is large enough.
Cloud Computing Vision
If computers of the kind I have advocated become the computers of the future, then computing may some day be organized as a public utility, just saw the telephone system is a public utility … The computer utility could become the basis of a new and important industry.
Based on this vision, cloud computing should turn the IT resource into a fungible utility.
We shouldn't need to care about which hardware resources are used, or where they are. Virtualization technology is definitely an enabler in this process.
Unfortunately, some limitations exist. For example, even with virtualization, they are some hardware dependencies that cannot be masked. In addition, different providers support different APIs; thus, we cannot seamlessly switch amongst providers without rewriting code. In addition, there are privacy/security concerns associated with putting core business code in the hands of an external provider.
Cloud Deployment Models
In public clouds, the infrastructure belongs to the cloud provider, and third party customers/tenants can rent the hardware to perform their computational tasks.
In private clouds, the infrastructure and software is owned by the same entity. Cloud computing technology is leveraged to maintain some of the flexibility/elasticity on machines that are in-house.
Hybrid clouds combine public and private clouds. Private clouds may comprise the main compute resources for the applications, with failover/spikes being handled on public cloud resources. In addition, public clouds may be used for auxiliary tasks, such as load testing.
Finally, community clouds are public clouds that are used by certain types of users.
Cloud Service Models
Clouds are often differentiated based on the service model that they provide.
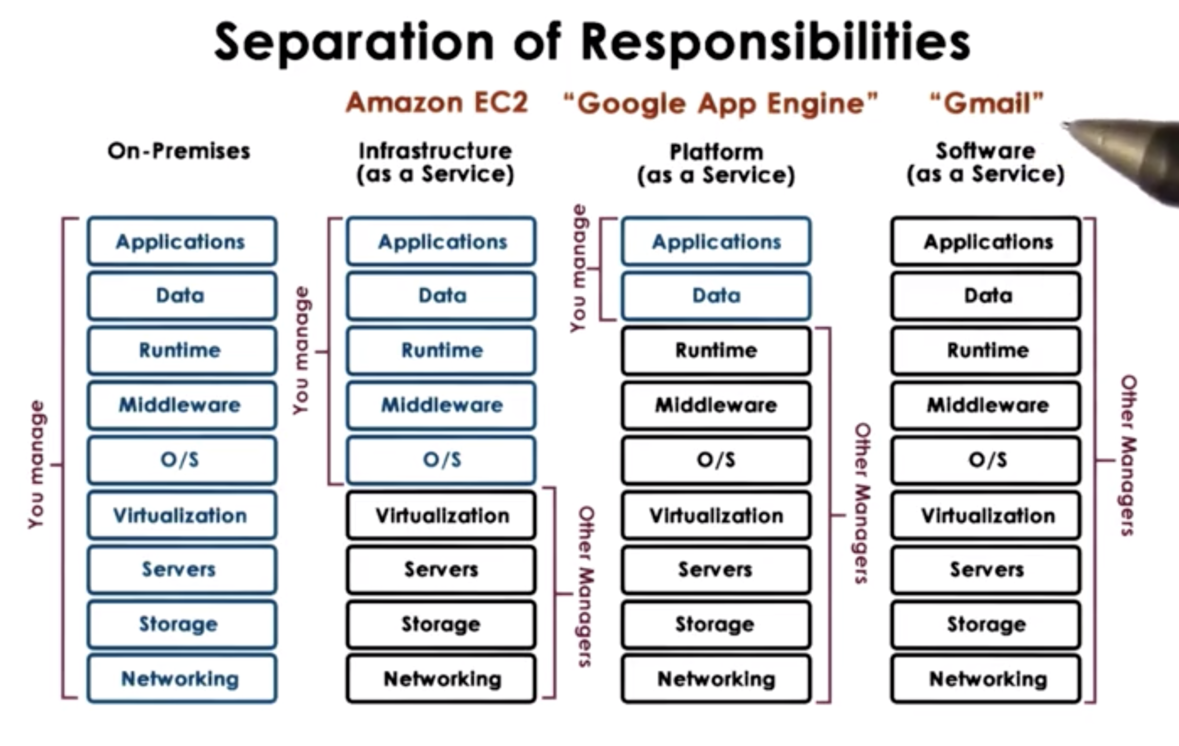
Without the use of cloud computing, you run your application on premises, which means you have to take care of everything yourself.
At the other extreme, you can use cloud computing services to provide you with a complete application. This is what we call Software as a Service (SaaS). Gmail is a great example of a SaaS platform.
A Platform as a Service (PaaS) provides you with certain APIs to allow you to develop certain types of applications. The platform provides an execution environment, which includes the OS and other tools necessary for the application to run in that environment. Google App Engine is an example of a PaaS platform. This PaaS provides everything needed to develop android applications.
At the lowest level, clouds can provide infrastructure instances, like compute instances that consist of the CPUs with accompanying memory, storage and network infrastructure. Amazon EC2 is a such a model of this Infrastructure as a Service (IaaS).
These types of clouds still don't provide access to the physical resources directly, rather only the virtualized resources. It is often the case that you are sharing the physical resources with other tenants. That being said, Amazon does provide high-performance instances that are single tenant.
Requirements for the Cloud
Clouds must provide fungible resources. This means that the resources can easily be repurposed to support different customers with different types of requirements. Without fungibility, the economic opportunity for cloud providers disappears.
Clouds must integrate resource management methods that support the premise of cloud computing. They must be able to dynamically adjust the resources that are allocated to cloud users depending on need.
Such management methods must be able to operate at very large scale - up to tens of thousands of nodes. Scale is important for both the cloud provider, in terms of resource management, and in terms of the customer, in terms of on-demand resource allocation.
Once scale is introduced, failures become inevitable. The probability of system failure increases with the number of components in the system, which each have an independent probability of failure. We have to incorporate mechanisms to deal with failures.
Clouds are shared resources, so cloud management has to provide mechanisms that guarantee performance and isolation across these multi-tenant environments. Misbehaving tenants should not be able to wreak havoc on other tenants and/or the entire system.
Clouds must also make guarantees with regards to the safety of their client's data and the security of the execution environment that they provide to their clients.
Cloud Enabling Technologies
A number of technologies are needed in order for cloud computing to be performed correctly and efficiently.
Virtualization technologies is needed to provide fungible resources that can be dynamically repurposed for different customer needs.
In addition, resource-provisioning and -scheduling technologies are required to make sure that cloud resources can be spun up quickly, consistently, and efficiently. mesos and yarn are technologies that address this issue.
In order to address customers' needs for scale, cloud technologies need to provide abilities to process and store large amounts of data. Hadoop MapReduce and Spark are popular technologies for big data.
Regarding data storage, cloud computing platforms incorporate distributed filesystems - that typically operate in some "append only" mode. In addition, NoSQL databases and distributed in-memory caches can also help with accessing and manipulating data at scale.
Cloud users need to be isolated from one another. Cloud computing technologies need software that can enable and configure these defined slices of resources.
Finally, cloud computing platforms must incorporate efficient monitoring technologies in order to regulate cloud resources. This is useful for the cloud provider to preside over the data center as a whole, but also as a service made available to cloud customers who may wish to interact with their application logs in an efficient way. Flume, CloudWatch, Log Insight are all monitoring technologies.
The Cloud as a Big Data Engine
One benefit of cloud computing is that it empowers anyone to have potentially infinite resources. As long as you can pay, you can have the resources that are required to work on hard, data- and resource-intensive problems.
Cloud platforms that offer big data processing as a service need - at a minimum - a data storage layer and a data processing layer.
Often, these services incorporate a caching layer as well. Remember that cache access is quick, and repeated cache access can definitely speed up the execution of an application.
Commonly, big data stacks incorporate some language front-end that allows developers to query their data in a language that they are familiar with (like SQL or Python).
People are often interested in analytics and mining when it comes to big data. As a result, big data platforms often incorporate a machine learning suite of commonly used algorithms, applications, and visualizations.
Finally, the data being analyzed with these platforms is often continuously being generated, which means that these platforms needs to have support for ingesting and staging data that is continuously being streamed into the platform.
Example Big Data Stacks
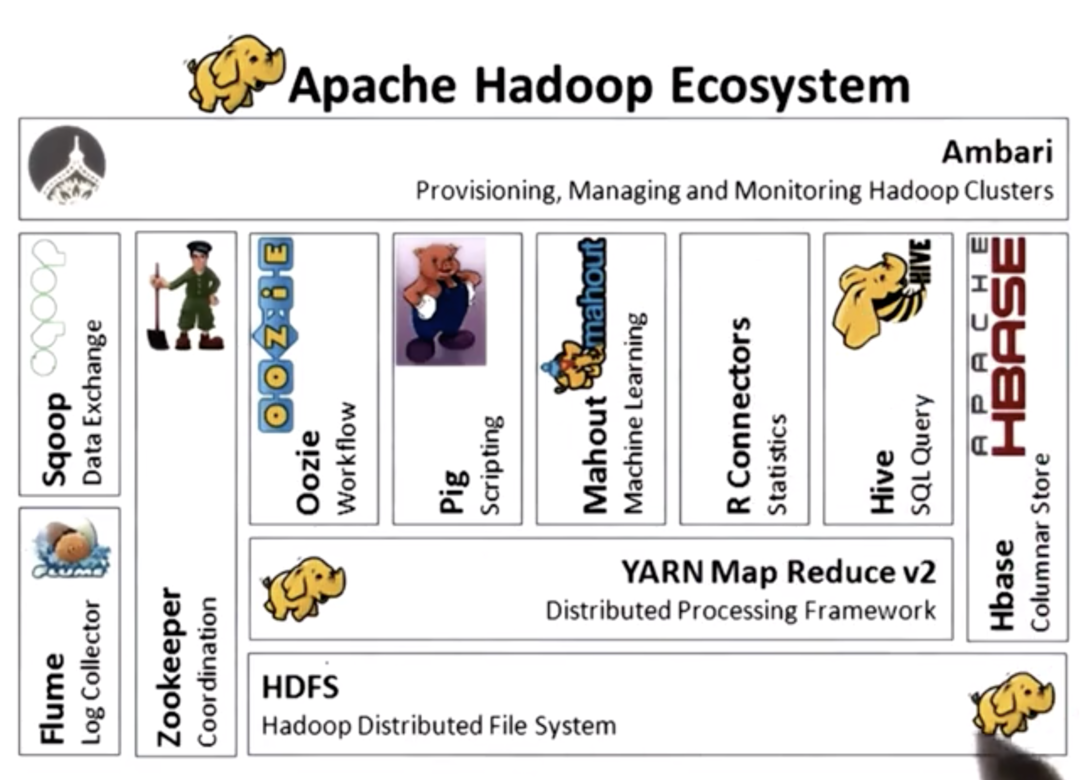
Hadoop
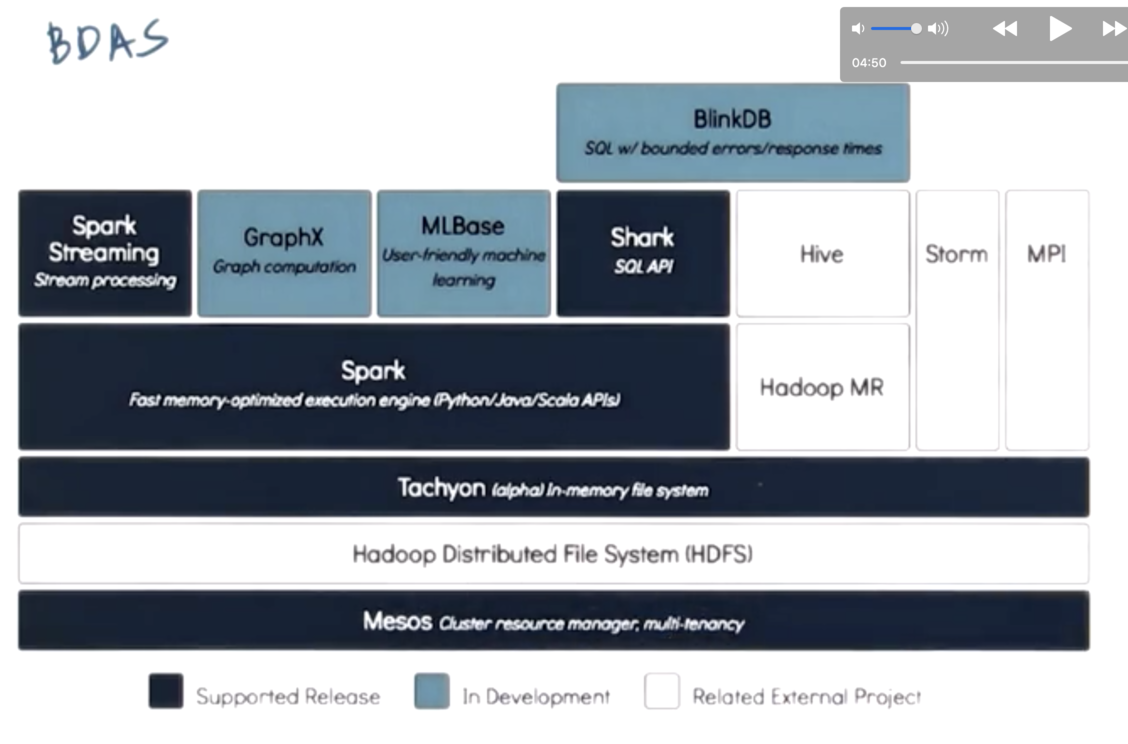
Berkeley Data Analytics Stack (BDAS)
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy