Operating Systems
Remote Procedure Calls
19 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Remote Procedure Calls
Why RPC?
Let's look at two applications. In the first application, the client gets a file from the server. In the second application, the client sends an image to the server for some processing/modification.

Note that the setup required for both applications is very similar, even identical at points. The only difference, really, is the request being made from the client to the server, and the data being transmitted.
Almost all programs that implement some kind of basic client/server functionality will require these very similar setup steps, and thus it is productive to simplify this process. This need for simplification gave rise to RPC.
Benefits of RPC
RPC is intended to simplify the development of interactions across address spaces and machines.
One benefit of RPC is that it offers a high-level interface for data movement and communication. This means that the developer can focus more on what their application does as opposed to the standard boilerplate setup.
RPC also handles a lot of the errors that may arise from low-level communication/transmission interactions, freeing the developer from having to explicitly re-implement error handling in each program.
Finally, RPC hides complexities of cross-machine interactions.
RPC Requirements
The model of IPC interactions that the RPC model is intended for needs to match client/server interactions. The server performs some complex tasks, and the client needs to know how to communicate with that server.
Since most of the languages at the time were procedural languages (hence the name remote procedure call), there was an expectation that this model followed certain semantics. As a result, RPCs have synchronous call semantics. When a process makes a remote procedure call, the calling process will block until the procedure completes and returns the result. This is the exact same thing that happens when we make a local procedure call.
RPCs also have type checking. If you pass an argument of the wrong type to an RPC, you will receive some kind of error. Type checking affords us opportunities to optimize the implementation of the RPC runtime. When packets are being sent between two machines, they are just a stream of bytes. Being able to transmit some information about the types can be useful when the RPC runtime is trying to interpret the bytes.
Since the client and the server may run on different machines, there may be differences in how they represent certain data types. For instance, machine may differ in their endianness, in their representation of floating point numbers, negative numbers and so on. The RPC system should hide these differences from the programmer, ensuring that the data is correctly transported and converted.
One way to deal with the conversion is for the RPC runtime, and both endpoints to agree upon a single data representation; for example, network format of integer types. With this agreement, there is no need for endpoints to negotiate on how data should be encoded.
Finally, RPC is meant to be more than a transport-level protocol. RPC should support different types of protocols - whether UDP, TCP or others - to communicate. RPC should also incorporate some higher level mechanisms like access control, authentication, and fault tolerance.
Structure of RPC
The client wants to perform some addition but doesn't know how. The server is the calculator. In this scenario, the client needs to send the operation it wants to perform as well the data needed to perform that operation over to the server. The server contains the implementation of that operation, and will perform it on behalf of the client.
We can use RPC to abstract away all of the low-level communication/transport details.
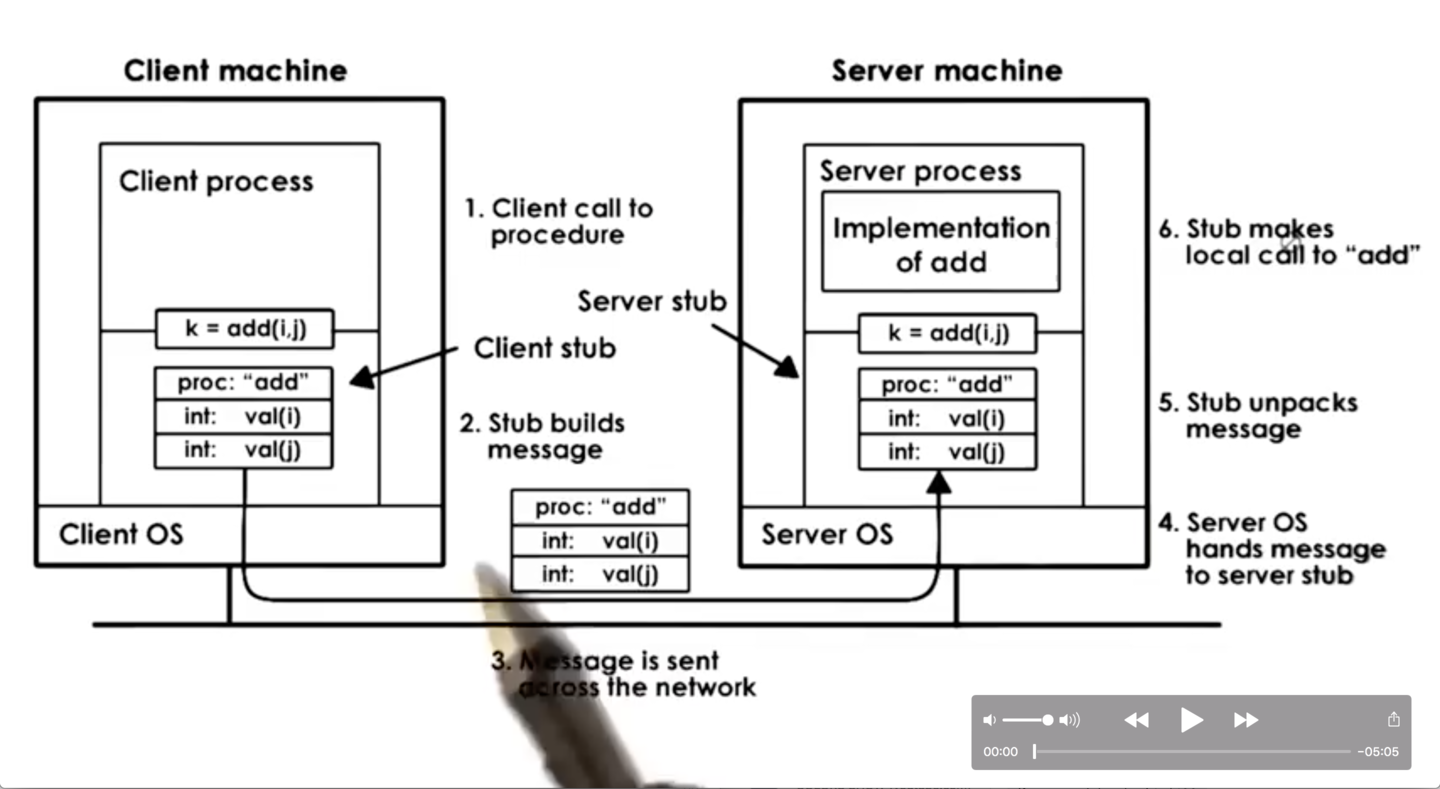
Client
With RPC, the client is still allowed to call the function add with i and j, even those the client doesn't hold the implementation of the add function.
In a regular program, when a procedure is called, the execution jumps to some other point in the address space where the implementation of that procedure is actually stored. In this example, when the client calls add, the execution will also jump to another location in the address space, but it won't be where the implementation of add lives. Instead, it will be in a stub implementation. To the rest of the process, this stub will look like the real add.
The responsibility of the client stub is to create a buffer and populate that buffer with all of the appropriate information - the function name (add) and the arguments i and j in this case. After the buffer is created, the RPC runtime sends the buffer to the server process. This may be via TCP/IP sockets or some other transport-level protocol.
The stub code itself is automatically generated via some tools that are part of the RPC package; that is, the programmer doesn't have to write the stub code.
Server
When the packets are received on the server, they are handed off to the server stub. This stub knows how to parse all of the received bytes, and it will be able to determine that this is an RPC request for add with the arguments i and j.
Once this information is extracted, the stub is ready to make a call in the server process to the local add function with i and j.
The server will then create a buffer for the result and send it back to the client via the appropriate connection. The packets will be received by the client stub, and the information will be stored in the client address space.
Finally, the client function will return. The result of the call will be available, and client execution will proceed.
Steps in RPC
Let's summarize the steps that have to take place in an RPC interaction between a client and a server.

In the first step, a binding occurs. The client finds and discovers the server that supports the functionality it needs. For connection-based protocols (like TCP/IP), the actual connection will be established in this step.
In the second step the client makes the actual RPC call. Control is passed to the stub, blocking the rest of the client.
The client stub then creates a data buffer, and populates it with the arguments that are passed in. This process is called marshaling. The arguments may located in noncontiguous memory locations within the client address space. The transport level, however, requires a contiguous buffer for transmission. This is why marshaling is needed.
Once the buffer is available, the RPC runtime will actually send the message to the server, via whatever transmission protocol the client and server have agreed upon during the binding process.
The data is then received by the RPC runtime on the server machine, which performs all of the necessary checks to determine which server stub the request needs to be delivered to.
The server stub will unmarshall the data, extracting the necessary byte sequences from the buffer and populating the appropriate data structures.
Once the arguments are allocated and set to the appropriate values, the actual procedure call can be made. This calls the implementation of the procedure that is actually part of the server process.
The server will compute the result of the operation, which will be passed to the server side stub and returned to the client.
Note that before the client can bind to the server, the server must do something to let the world know it can be found. The server must execute a registration step to let the world know what procedures it supports, what arguments it requires, and what location it can communicated with at.
Interface Design Language
When using RPC, the client and the server don't need to be developed together. The can be written by different developers in different programming languages.
For this to work, however, there must be some type of agreement so that the server can explicitly say what procedures it supports and what arguments it requires.
This information is needed so that the client can determine which server it needs to bind with.
Standardizing how this information is represented is also important because it allows the RPC runtime to incorporate some tools that allow it to automate the process of generating the stub functionality.
To address these needs, RPC systems rely on the use of interface definition languages (IDLs). The IDL serves as a protocol of how the client-server agreement will be expressed.
Specifying an IDL
An interface definition language is used to describe the interface that particular server exports. At a minimum, this will include the name of the procedure, the types of the different arguments and the result type.
Another important piece of information to include is a version number. If there are multiple servers that provide the same procedure, the version number helps clients find which server is the most up to date. In addition, version numbers allow clients to identify the server which has the version of the procedure that fits with the rest of the client program.
An RPC system can use an IDL that is language-agnostic. SunRPC uses an IDL called eXternal Data Representation (XDR). XDR is a different specification from any programming language. An RPC system can also use an IDL that is language-specific. For example, the Java RMI uses Java.
For programmers that know the language, a language-specific IDL is great. For programmers that don't know that language, learning a language-agnostic IDL is simpler than learning a whole new programming language.
Whatever the choice of IDL, the IDL is used solely to define the interface. The IDL is used to help the RPC system generate stubs and to generate information that is used in the service discovery process.
The IDL is not used for the implementation of the service.
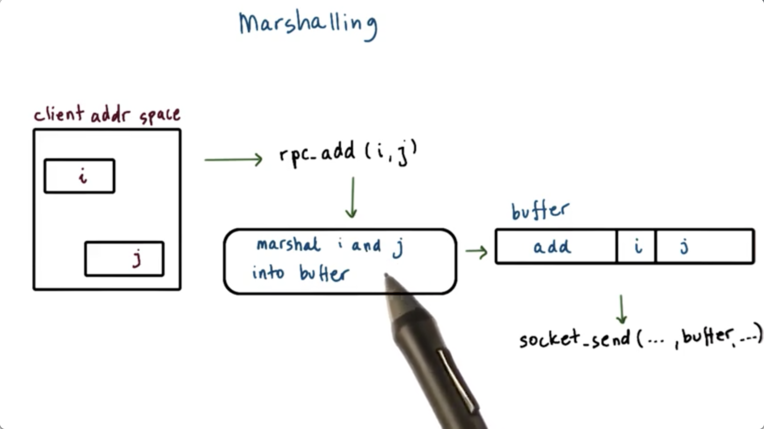
Marshaling
To understand marshaling, let's look at the add example again, with arguments i and j. Initially, i and j live somewhere in the client address space. When the client calls the add function, it passes in i and j as discrete entities.
At the lowest level, a socket will need to send a contiguous buffer of information over to the server. This buffer will need to hold a descriptor for the procedure (add) to be called on the server, as well as the necessary arguments, i and j.
This buffer gets generated by the marshaling code.
Generally, the marshaling process encodes the data into an agreed upon format so that it can be correctly interpreted by the server. This encoding specifies the layout of the data upon serialization into a byte stream.
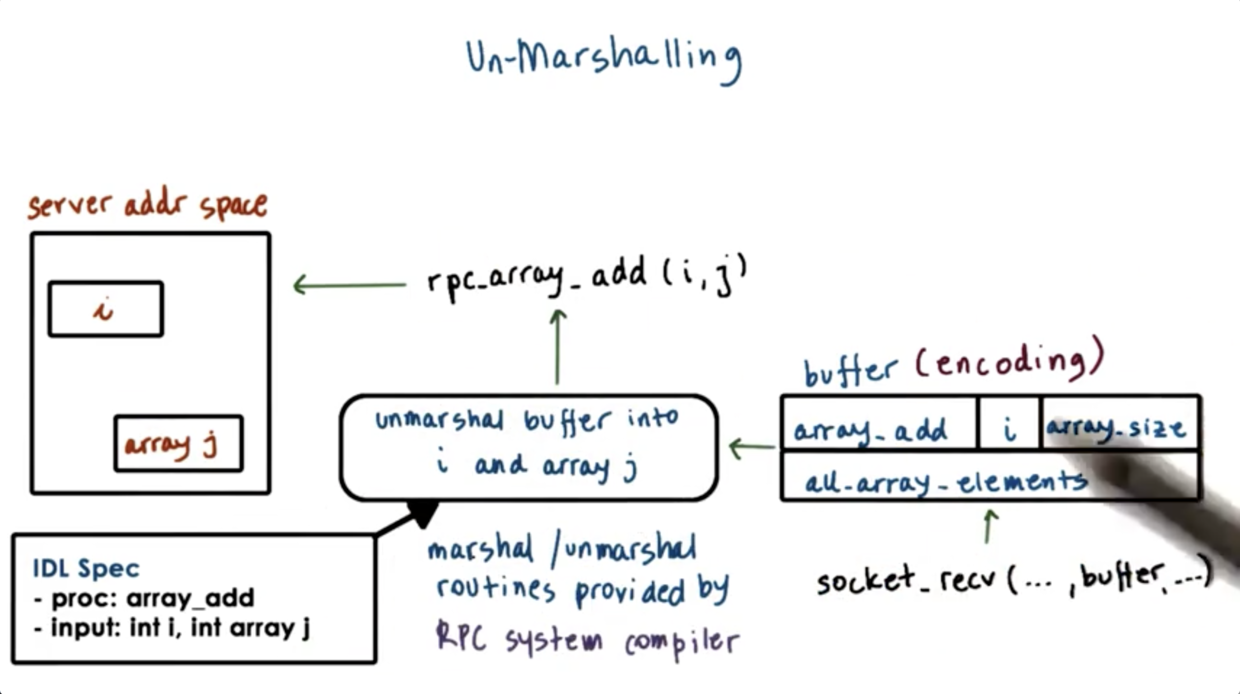
Unmarshalling
In the unmarshalling code, we take the buffer provided by the network protocol and, based on the procedure descriptor and the type of arguments required by the described procedure, we extract the correct chunks of bytes from the buffer and use those bytes to initialize data structures that correspond to the argument types.
As a result of the unmarshalling process, the i and j variables will be allocated in the server address space and will be initialized to values that correspond to whatever was placed into the buffer sent by the client.
The marshaling/unmarshalling routines are generally not written by the programmer. RPC systems typically include a special compiler that takes an IDL specification and generates the marshaling/unmarshalling routines from that. The programmer just needs to ensure that they link these autogenerated files with their program files.
 -
-
Binding and Registry
Binding is the mechanism used by the client to determine which server to connect to, based on the service name and the version number. In addition, binding is used to determine how to connect to a particular server; basically, to discover the IP address and/or network protocol required for the client/server connection to be established.
To support binding, there needs to be some systems software that maintains a database of all available services. This is often called a registry.
A registry is essentially the yellow pages for services: you pass the registry the name of the service and the version you are looking for, and you receive the contact information for the matching server. This contact information will include the IP address, port, and transport protocol.
At one extreme, this registry can be some distributed online platform where any RPC service can register.
On the other hand, the registry can be a dedicated process that runs on every server machine and only knows about the processes running on that machine. In this case, clients must know the machine address of the host running the service, and the registry need only provide the port number that the service is running on.
The registry needs some sort of naming protocol. The simplest approach requires that the client specifies the exact name and version number of the service it requires. A more sophisticated naming scheme may be able to consider synonyms. In this case, requesting the sum service might still get you the add service.
Pointers in RPC
In regular local procedures, it makes sense to allow pointer arguments. The pointer references some address within the address space of both the calling procedure and the called procedure, so the pointer can be dereferenced with no issue.
In RPC, this makes no sense. The pointer points to some particular data in the caller address space, and some arbitrary data in the remote address space.
To solve this problem, an RPC system can disallow pointers to be used an arguments to any RPC procedure.
Another solution allows pointers to be used, but ensures that the referenced data - not the pointer - is marshaled into the transmitted buffer.
On the server side, once the data is unpacked, the unmarshalling code will pass the address of this data to the local procedure.
In this way, RPC allows pointers to be "passed" between the client and the server.
Handling Partial Failures
When a client hangs while waiting on a remote procedure call, it is often difficult to pinpoint the problem.
Is the server down? Is the service down? Is the network down? Is the message lost?
Even if the RPC runtime incorporates some timeout/retry mechanisms, there are still no guarantees that the problem will be resolved or that the runtime will be able to provide some better insight into the problem.
RPC systems incorporate a special error notification that tries to capture what went wrong with an RPC request without claiming to provide the exact detail. This serves as a catch all for all types of (partial) failures that can potentially happen during an RPC call.
What is SunRPC?
SunRPC is an RPC package originally developed by Sun in the 1980s for UNIX systems. It is now widely available on other platforms.
SunRPC makes the following design choices.
In SunRPC, it is assumed that the server machine is known up front, and therefore the registry design choice is such that there is a registry per machine. When a client wants to talk to a particular service, it must first talk to the registry on that particular machine.
SunRPC makes no assumption regarding the programming language used by the client or the server. Sun RPC relies on a language-agnostic IDL - XDR - which is used both for the specification of the interface and for the specification of the encoding of data types.
SunRPC allows the use of pointers and serializes the pointed-to data.
SunRPC supports mechanisms for dealing with errors. It includes a retry mechanism for re-contacting a server when a request times out. The number of retries can be specified.
The RPC runtime tries to return meaningful errors as often as possible.
SunRPC Overview
SunRPC allows the client to interact via a procedure call interface.
The server specifies the interface that it supports in a .x file written in XDR. SunRPC includes a compiler called rpcgen that will compile the interface specified in the .x file into language-specific stub for the client and the server.
On start, the server process registers itself with the registry daemon available on the local machine. The per-machine registry keeps track of the name of the service, the version, the protocol, and the port number. A client must explicitly contact the registry on the target machine in order to obtain the full contact information about the desired service.
When the binding happens, the client creates an RPC handle, which is used whenever the client makes any RPC calls. This allows the RPC runtime to track all of the RPC-related state on a per-client basis.

SunRPC XDR Example
Here is the XDR specification for a simple program in which the client sends an integer x to the server and the server squares it.

In the .x file, the server specifies all of the datatypes that are needed for the arguments and the results of the procedures that it supports.
In this case, the server supports one procedure SQUARE_PROC that has one argument of the type square_in, and returns a result of the type square_out.
The datatypes square_in and square_out are both defined in the .x file. They are both structs that have one member that is an int, which is just like the ints in C.
In addition to the data types, the .x file describes the actual RPC service and all of the procedures that it supports.
First, there is the name of the RPC service, SQUARE_PROG, that will be used by clients trying to find an appropriate service to bind with.
A single RPC server can support one or more procedures. In our case, the SQUARE_PROG service supports one procedure SQUARE_PROC. There is an ID number associated with a procedure that is used internally by the RPC runtime to identify which particular procedure is being called.
In addition to the procedure ID, and the input and output data types, each procedure is also identified by a version. The version applies to an entire collection of procedures.
Finally, the .x file specifies a service id. This id is a number that is used by the RPC runtime to differentiate among different services.
The client will use service name, procedure name, and service number, whereas the RPC runtime will refer to the service id, procedure id, and the version id.

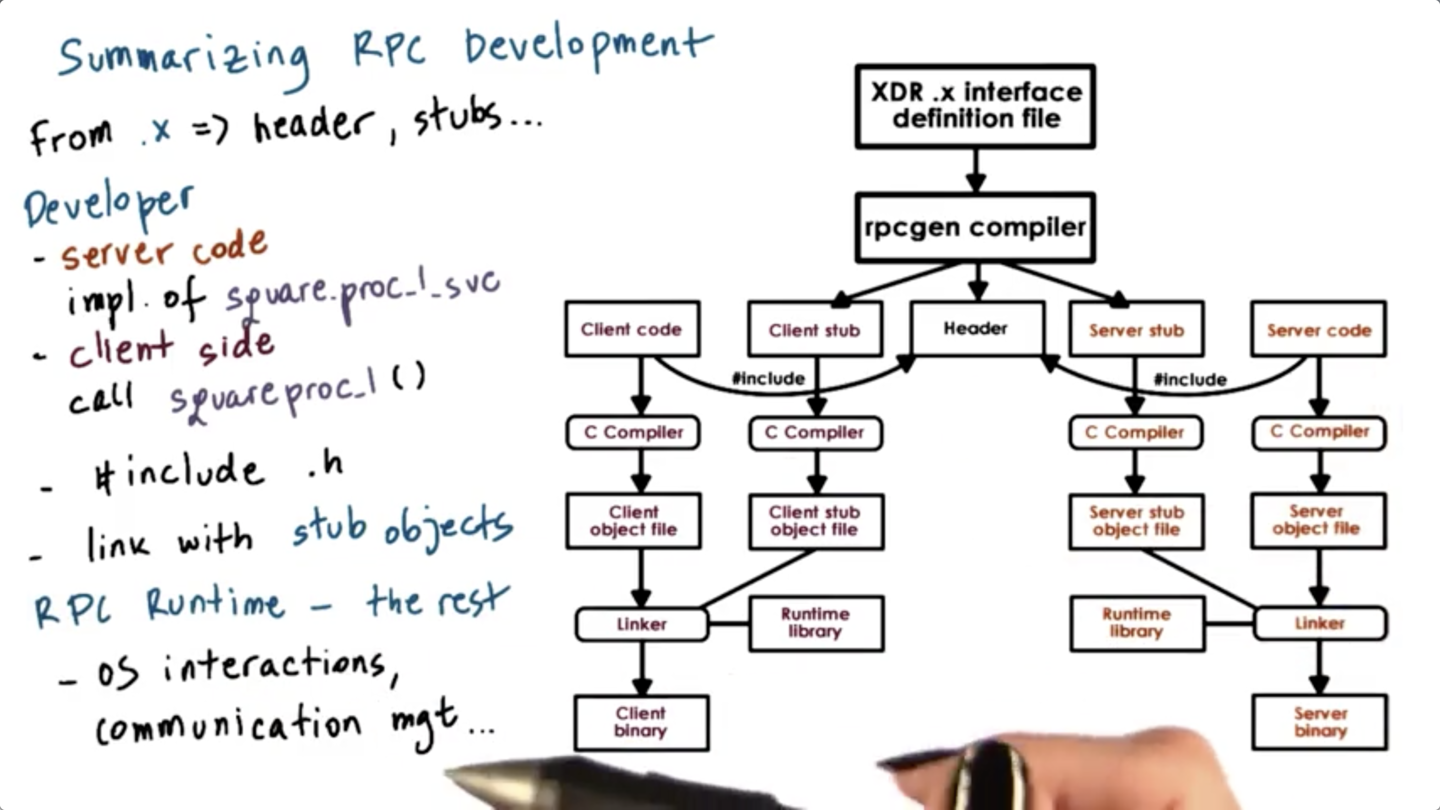
Compiling XDR
To generate the client/server C stubs from the interface defined in the .x file, run
rpcgen -C <interface>.xThe outcome of this operation generates several files.
<interface>.h contains all of the language specific definitions of the datatypes and the function prototypes.
<interface>_svc.c contains the code for the server side stub and <interface>_clnt.c contains the code for the client side stub.
The compilation steps also generates <interface>_xdr.c which contains code for marshaling/unmarshalling routines that will be used by both the client and the server.
The first part of <interface>_svc.c contains the main function for the server which includes code for the registration step and also some additional housekeeping operations. The second part contains all of the code that is related to the particular RPC service. This code handles request parsing and argument marshaling.
In addition, the autogenerated code will include the prototype for the actual procedure that is invoked in the server process. This has to be implemented by the developer.
The client stub will include a procedure that is automatically generated and this will represent a wrapper for the actual RPC call that the client makes to the server-side process.
Once we have this, the developer can just call the function.

Summarizing XDR Compilation
By default, rpcgen generates code that is not thread safe. To generate thread safe code use:
rpc_gen -C -M <interface>.xThe -M flag doesn't actually give a multithreaded server, rather it ensures that the code produces will be thread safe.
To actual generate a multithreaded server, you can pass the -A flag on Solaris. In Linux, a multithreaded server needs to be implemented manually.
SunRPC Registry
The code that the server needs in order to register with the registry is autogenerated as part of the rpcgen compilation step.
In SunRPC, the registry process runs on every machine, and is called portmapper. To start this process on Linux, run
sudo /sbin/portmapThis is the process that needs to be contacted both by the server when it wishes to register its service, and by the client when it needs to find the specific contact information for a given service.
Once the RPC daemon is running, we can check the services that are running with it using
/usr/sbin/rpcinfo -pThis command will return the program id, version, protocol, socket port number, and service name for every service running on that machine.
Portmapper itself is registered with both TCP and UDP protocols on socket 111.
SunRPC Binding
The binding process is initiated by the client using the following operation
CLIENT* clnt_create(char* host, unsigned long prog, unsigned long vers, char* proto);For the SQUARE_PROG service we created above, the call would look like
CLIENT* clnt_handle;
clnt_handle = clnt_create(rpc_host_name, SQUARE_PROG, SQUARE_VERS, "tcp");SQUARE_PROG and SQUARE_VERS are autogenerated from the compilation of the XDR file and will be included in header file as #define'd values.
The return from this function is the client handle that will be used in every subsequent RPC call. This handle can also be used to track the status of the current request, as well as handle any error messages or authentication related information.
XDR Data Types
All of the types defined in the XDR file must be XDR-supported data types.
Some of the default XDR data types include:
- char
- byte
- int
- float
XDR also support a const datatype which will get compiled into a #define'd value in C.
hyper values correspond to 64-bit integers and quadruples refer to 128-bit floats.
The opaque type corresponds to uninterpreted binary data, similar to the C byte type. For instance, if you wanted to transfer an image, that image could be represented as an array of opaque elements.
XDR support two types of arrays: fixed-length and variable-length. A fixed length array looks like int data[80].
A variable-length array looks like int data<80>. When compiled, this will translate into a data structure that has two fields: an integer len that corresponds to the actual size of the array, and a pointer val that is the address of where the data in this array is actually stored.
When the data is sent, the sender has to specify len and set val to point to the memory location where the data is stored. On the receiving end, the server will know that it is expecting a data structure that is of variable length, so it will know to read the first four bytes to determine the length to determine the size of the array, and then to allocate the appropriate amount of memory and copy the remaining portion of the incoming byte stream into that buffer.
The only exception to this strings. In memory, strings are stored as normal null-terminated strings. When the string is encoded for transmission, it will be stored as a par of len and data.
XDR Routines
The marshaling/unmarshalling routines will all be found in the <interface>_xdr.c file.
In addition, the compiler will generate some cleanup operations, like xdr_free that will be used to free up memory regions that are allocated by the various RPC operations. These routines will typically be called within a procedure named *_freeresult. This is another user-defined procedure where the user can specify the pieces of state that need to be deallocated after the runtime is done servicing the RPC request. The RPC runtime will automatically call this procedure after it is done computing the results.
Encoding
Since the server can support multiple programs, versions, and procedures, it is not enough just to pass procedure arguments from client to server.
RPCs must also contain information about the service procedure id, version number and request id in the header of the request. This header will be included in the response from the server as well.
In addition to these metadata fields, we clearly need to put the actual data (arguments or results) onto the wire. These datatypes are encoded into a byte stream which depends on the data type.
There may be a 1-1 mapping between how the data is represented in memory and how it is represented on the wire, but this may not always be the case. What is important is that the data is encoded in a standard format that can be deserialized by both the client and server.
Finally, the packet of data needs to be preceded by the transport header (TCP/UDP) in order to actually be sent along the wire in accordance with these transmission protocols.
XDR Encoding
In addition to providing an IDL, XDR also defines an encoding; that is, the binary representation of our data "on the wire".
All data types are encoded in multiples of four bytes. Encoding a single byte argument therefore would take and 3 bytes of padding.
Big endian is used as the transmission standard. Regardless of the endianness of the client or the server, every communication will require that the data be converted to the big endian representation prior to transmission.
Other encoding rules include:
- two's complement representation of integers
- IEEE format for floating point numbers

Java RMI
Another popular RPC system is Java Remote Method Invocations (Java RMI).
This system was also pioneered by Sun as a form of client/server communication methods among address spaces in the JVM.
Since Java is a an object-oriented language, and entities interact via method invocations, not procedure calls, the RPC system is appropriately called RMI instead.
Since all of the generated code is in Java, and the RMI system is meant for address spaces in JVMs, the IDL is language-specific to Java.
The RMI runtime is separated into two components.
The Remote Reference Layer contains all of the common code needed to provide reference semantics. For instance, it can support unicast (a client interacting with a single server), or broadcast (a client interacting with multiple servers). In addition, this layer can specify different return semantics, like return-first-response and return-if-all-match.
The Transport Layer implements all of transport protocol-related functionality, whether TCP, UDP, shared memory or something else.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy