Databases
Fundamentals of Databases
20 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Fundamentals of Databases
Overview
We define a database as a model of reality, a definition that raises two important questions:
- Why use models at all?
- When is it appropriate to use a database management system (DBMS) to create such a model?
Why Use Models
Why should we use models at all? First, models help us examine and manage parts of the real world. Second, the costs of implementing a model are often considerably lower than the costs of using or experimenting with reality.
We can build models that correspond to many different slices of reality. For example, we can create a model of the US economy, which might allow us to observe the effects of proposed laws before implementing them in society. We might model a tsunami warning system that we could use to save humans, crops, and livestock. A model that simulates traffic can aid in determining where to build roads.
A fundamental problem we encounter when building models is that we must agree on the reality we want to represent and the elements of reality we've chosen to include in our model.
A Map is a Model of Reality
Consider this map of the world.

What's wrong with it? First, we typically expect north to face "up" on a map. Let's fix that.

North is now "up," but the countries are not to scale; South America, for example, looks too thin. The map also portrays land with the color blue, yet we generally expect water to be blue and land to be green or tan.
Here is a map where everything looks right.

From this example, we can see that using models to communicate information effectively requires first establishing and conforming to a set of shared expectations.
Map Example
Let's look at a more detailed map, this time of Atlanta, Georgia.
This map contains a language to describe reality. In that language, different colors label different kinds of roads. For example, the map depicts US Interstate system roads in blue, state highways in green, and more minor roads in yellow.
We have letters available to spell the names of places, such as the East Point and College Park neighborhoods. We have symbols available to indicate forests, airports, and other points of interest.
It's important to understand that a model may contain errors. This map might be outdated, describing aspects of reality that have changed since its publication, or it might be flat-out wrong and convey a world that never existed.
A model may contain information that is useful but doesn't have any physical counterpart in reality. For example, maps may have contour lines, which we create to help us better visualize topography.
Users must share some common knowledge before they can communicate through a model. For example, we assume when looking at this map that north is "up" and that the relative sizes of places are represented on an appropriate scale. For example, the font size of the word "Atlanta" is larger than "East Point," presumably conveying that the former is larger than the latter.
Why use a model instead of solely interacting with the real world? Consider traveling from point A to point B in a new area with and without a map. We can wander about, hoping that we are moving closer to the destination, or we can use a map to travel directly to it.
A Message to Model Makers
A model is a means of communication, and the users of a model must share a certain amount of knowledge to communicate through that model. We saw this requirement when looking at maps; as we said, north must be "up," the continents must be scaled accurately, and the colors have to be suitable for us to understand what the map is depicting.
Remember that a model only emphasizes certain aspects of reality - those that are useful for the task at hand.
Models can have their own language through which they communicate concepts. On the map, we saw a language of symbols, letters, and numbers that reflected aspects of reality. We need to agree on and understand what that language is to communicate through that model.
Models can be erroneous because they are fallible representations of reality. For example, a map can have a road placed in the wrong location.
To enhance the model, we may add features to it that do not exist in reality. In maps, we can contour lines on a mountain, the dateline, and other helpful constructs.
To Use or not to Use
Having now discussed why models might be helpful to us when we want to examine or manage pieces of reality, let's talk about when we want to use a database management system to create and use these models and when we might not want to use such a system.
To Use
Database management systems are good at supporting data-intensive applications. As opposed to process-intensive applications, data-intensive applications are those where a lot of data may flow between memory and secondary storage and between the user and the database.
Databases provide persistent storage of data, which means that even if our application loses power, our data will still be there tomorrow. Furthermore, databases offer backup and recovery utilities should the system go down.
Databases provide centralized control of data, an important feature that enables us to enforce policies across the database, even when that database is distributed. Databases provide access control and data security mechanisms.
Databases allow us to control redundancy, or the practice of storing data in multiple places. One might think it's essential to limit redundancy from an efficiency point of view, ensuring that we don't waste space retaining several copies of the same information.
The real benefit, however, is that controlling redundancy provides us with a mechanism for maintaining consistency and integrity. Consistency determines whether we can derive contradictions from within the database, which is impossible without redundancy.
Databases provide multi-user support and can support tens or hundreds of thousands of users accessing them simultaneously, such as flight reservation systems or point-of-sale transaction processing.
Databases contain documentation of the data structures available and required for practical use.
Data independence refers to the ability to change the implementation of a database to make it more efficient without affecting the user interface.
Not to Use
Despite the great functionality offered by database management systems, using a database management system is not always the right choice.
First, the initial investment in hardware, software, and training is very high. Some DBMSs are as large as operating systems, and the infrastructure needed to run them is expensive. Due to this complexity, the amount of time necessary to understand these systems can be considerable.
The generality provided by database management systems is not necessary for every use case. These systems contain robust support for security, concurrency control, and recovery. We may not need an industrial-grade level of security and may not have thousands of users accessing our data simultaneously. Maybe we don't need features like data independence because our data and applications are simple and stable.
Our application might have rigorous real-time requirements. A database management system is useless for those applications if it cannot run fast enough to support those requirements.
Outline of Major Topics
We will spend substantial amounts of time on data modeling and process modeling. It is possible to model perfectly but end up with a database application that doesn't run fast enough to be useful, so we will also spend some time discussing database efficiency.
Data Modeling
A model represents a perception of structures of reality, and the data modeling process has two steps: first, we fix our perception of reality, and; second, we represent that perception. We use the extended entity-relationship model to accomplish the first task and the relational model to express our perceptions inside the database. We use abstraction throughout the data modeling process, selecting only the aspects of reality that are important to us while ignoring the others.
Process Modeling
In process modeling, we aim to fix and represent our perception of processes of reality. Unlike in data modeling, in which we represent structures in the database, we represent processes via how we use the database through the database management system.
We can use the database through the database management system in two ways. We can embed data manipulation language (DML) statements in application code that access a database to update or retrieve data and display it in some interface. Alternatively, we can issue ad-hoc queries or updates on the database using the DML directly. SQL is the DML we will cover in this course.
Data Models, Database Architecture, and Database Management System Architecture
We perform data modeling using data models, which contain formalisms that allow us to express:
- data structures
- constraints
- operations
- keys and identifiers
- integrity and consistency
- null values
- surrogates
We decompose the architecture of a database into layers. This course will look at the ANSI/SPARC 3-level database architecture and the corresponding database management system architecture.
Additionally, we will define metadata and discuss its use and importance in databases.
Examples of Data Models
We defined a database as a model of structures of reality. A data model is the tool that we use to create such a model. Regardless of the specific data model we choose, we need one that allows us to express:
- data structures
- integrity constraints
- operations
We will use the entity-relationship model in this course to fix our perceptions of reality and the relational model to implement the entity-relationship model in a database management system.
Historically, the first database system, the IBM/IMS system, implemented a model known as the hierarchical model, in 1967. This model forms the basis of XML databases today.
Relational Models - Data Structures
We represent data using tables in the relational model. Consider the
following RegularUser table.
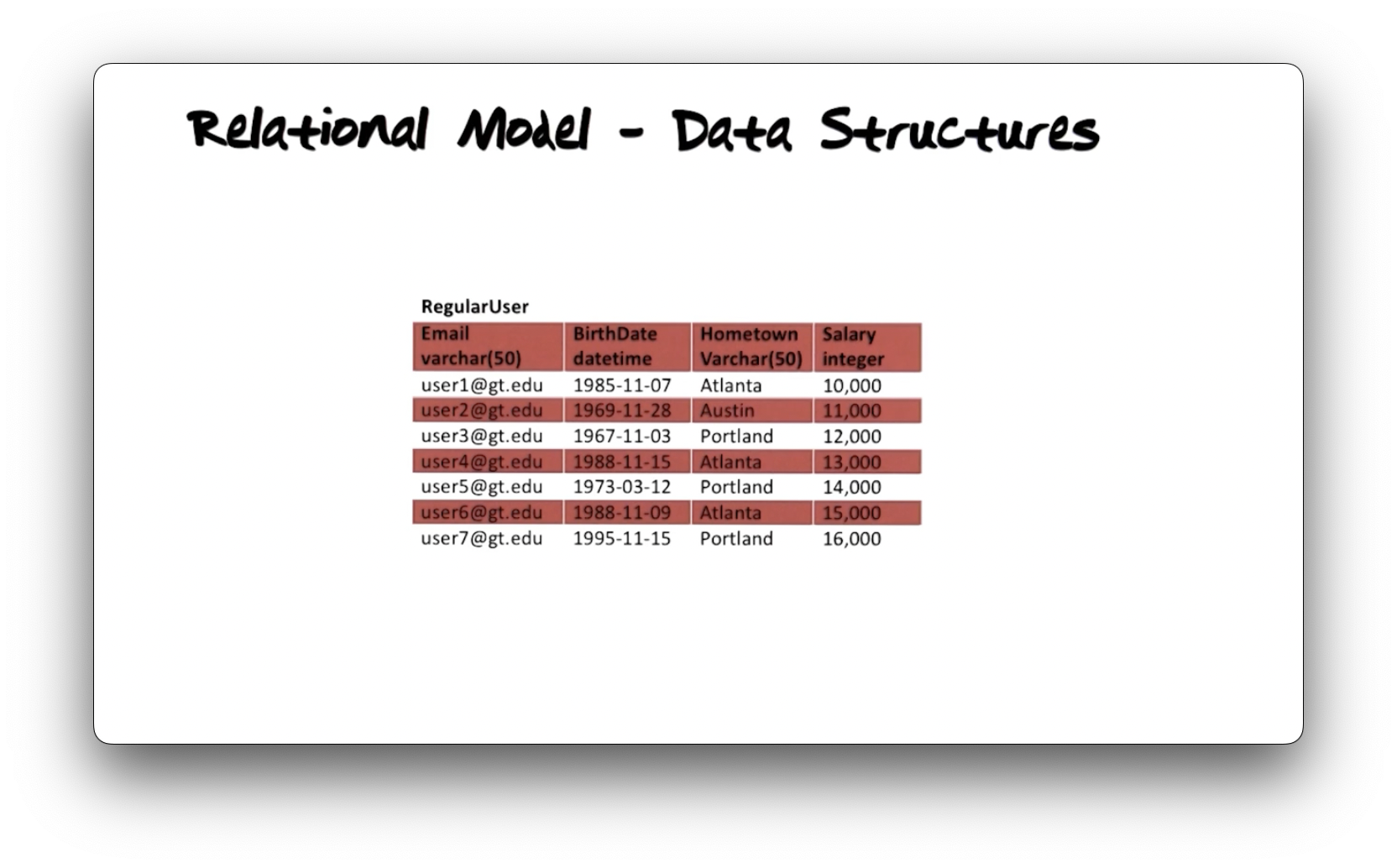
Tables have columns and rows. The number of columns is the degree of the
table, and the number of rows is the cardinality. The RegularUser table
has four columns and seven rows.
Each column has an associated data type that expresses the domain of values
permitted for entries in that column. The RegularUser type assigns the Email
and Hometown columns to the varchar(50) type, defined as variable-length
strings of at most fifty characters. The BirthDate column accepts datetime
values, and the Salary column accepts integer values.
Together, the table name, column names, and column data types constitute the
schema of the table. The schema defines the structure of data and is not
expected to change frequently. On the other hand, the rows express the current
state of reality as modeled by these structures. The RegularUser schema models
a perception of what a user is in our system, and the rows in that table
represent the individual user instances.
Relational Models - Constraints
Constraints are rules we define to restrict the data values permitted in our
system that we cannot express using a schema or column data types alone.
Consider the RegularUser table we just saw. We might want values in the
Email column to be unique and not NULL, allowing us to use emails to
uniquely identify users. We might constrain values in the BirthDate column to
be on or after January 1st, 1900. Finally, we might want to enforce that values
in the Hometown column must reference a city in the United States.
Data Model - Operations
We use operations to retrieve and change data. The following operation
inserts a new row (user) into the RegularUser table. This user lives in
Atlanta, makes $12,500 a year, was bored in August of 1992, and has the email
address user11@gt.edu.
insert into RegularUser
(user11@gt.edu, 1992-8-22, Atlanta, 12500)The following statement retrieves values from two columns in the RegularUser
table, Email and BirthDate, on the condition that the value in the
Hometown column is Atlanta and the value in the Salary column is greater
than 12,000.
select Email, BirthDate
from RegularUser
where Hometown='Atlanta' and Salary > 12000Which of the following users will the statement above select?
- user1@gt.edu, who is from Atlanta, born in 1985, with a salary of $10,000
- user4@gt.edu, who is from Atlanta, born in 1988, with a salary of $13,000
- user5@gt.edu, who is from Portland, born in 1973, with a salary of $14,000
The statement will select only the second user as they are the only user living in Atlanta and making more than $12,000.
Keys and Identifiers
A key is a uniqueness constraint. For example, we might decide to make the
Email column the primary key of the RegularUser table. As the key, this
column would require values in it to be unique so we could use them to uniquely
identify users.
Integrity and Consistency
Integrity describes how well the database reflects reality. For example, if a database lists my eye color as blue when my eyes are actually brown, we might say that database has poor integrity.
Consistency concerns how free a database is from any internal conflicts.
Let's compare the RegularUser table, which contains Email, BirthDate,
Name, and CurrentCity columns, and the User table, which has Email and
Address columns.

Let's look at consistency. The user with the email address user1@gt.edu has a
current recorded city of Atlanta in the RegularUser table but has an address
in the User table that refers to a location in Roswell. These two rows
highlight an inconsistency. The user identified as user4@gt.edu has a similar
inconsistency across the two tables.
This inconsistency arises because of redundancy between values in the
CurrentCity column of the RegularUser table and the city listed in the
Address column of the User table. Generally, determining when
inconsistencies appear is challenging, and, as a result, this database is not
particularly useful in determining where a user lives.
As an example of poor integrity, Professor Mark outlines a story in which his daughter - Louise Mark Christensen - is inferred to be a male because of her male middle name. The administrators of the database housing her information could improve its integrity by adding a column to store gender information explicitly. This way, inferences would not be necessary.
NULL Values
Let's expand the RegularUser table to include two new columns: SSRegist,
which represents whether a user has registered with the selective services; and
Sex, which represents the sex of the user. In the United States, males between
18 and 25 must register.

In this example, the user with the email user1@gt.edu is a male who has registered with selective services. The user with the email user6@gt.edu is also a male, but his registration status is 'Unknown'; sometimes, databases don't have complete information. The user with email user7@gt.edu has not registered, while the user with email user8@gt.edu has.
The remaining users are female, and thus values such as 'Yes,' 'No,' or 'Unknown' do not make sense. Instead, the registrations values for them are 'INAPPLICABLE. '
The null value 'Unknown' is acceptable; ideally, our database would hold meaningful values for all columns in all rows, but that is often not the case. However, the null value 'INAPPLICABLE' is problematic. We have designed a table in such a manner that several of the rows cannot have an applicable value for some of the columns.
We can avoid this problem by not designing tables whose columns only apply to
some subset of its rows. In this example, perhaps we would break out the notion
of selective services registration into its own table, whose rows are associated
with instances of the RegularUser table.
Surrogates - Things and Names
Let's say we have a set of regular users in reality, and we would like to record
their email, name, and address. We can create a RegularUser table in the
database with Email, Name, and Address columns.
Let's consider a hypothetical row in this table: user1@gt.edu, Lisa Smith, Roswell. If we look at the database a few days later, we might see:
user1@gt.edu, Lisa Jones, Roswell. Does this row describe the same user? Sure,
perhaps Lisa Smith got married to Mr. Jones and changed her last name. If we
look at the database a few days later still, we might see: user1@gt.edu, Lisa Jones, Atlanta. Is this still the same Lisa? Lisa Jones probably decided to
move to Atlanta with her new husband.
Finally, we might see this information next time we look at the database:
"user2@gt.edu, Lisa Jones, Atlanta". Is this the same Lisa? Everything we knew
about Lisa has changed, so it's hard to tell if the row references the same
person. In such a name-based representation system, a user exists solely as
what is known about them: no more, no less.
Consider an alternative way of implementing this table. Instead of having only
three columns - Email, Name, and Address - we add an extra column,
UserID, which stores system-generated unique identifiers. These surrogates
identify users in the real world even when everything else we know about them
changes.
ANSI/SPARC 3-Level DB Architecture: Separating Concerns
The data in a database is an extension of the schema, the instances of data values permitted by the schema. The schema, which defines the shape and types of data, is known as the intension. The separation of schema from data in database management systems makes data access more effective and efficient. When we want to retrieve data, we can write a query against the schema, and that query will return a result of all the data that fits the query.
If the database only consisted of one schema, then we would have to define what data means, how data is used, and how data should be organized and stored physically in that schema. Arranged so, queries through that schema would be able to reference how the data is physically organized, and changing that organization would impact higher-level applications.
The ANSI/SPARC three-level architecture defines three schemata: The conceptual schema concentrates on the meaning of data, the internal schema focuses on data storage, and the external schema concentrates on the use of data. The schema we have been discussing up to this point is the conceptual schema.
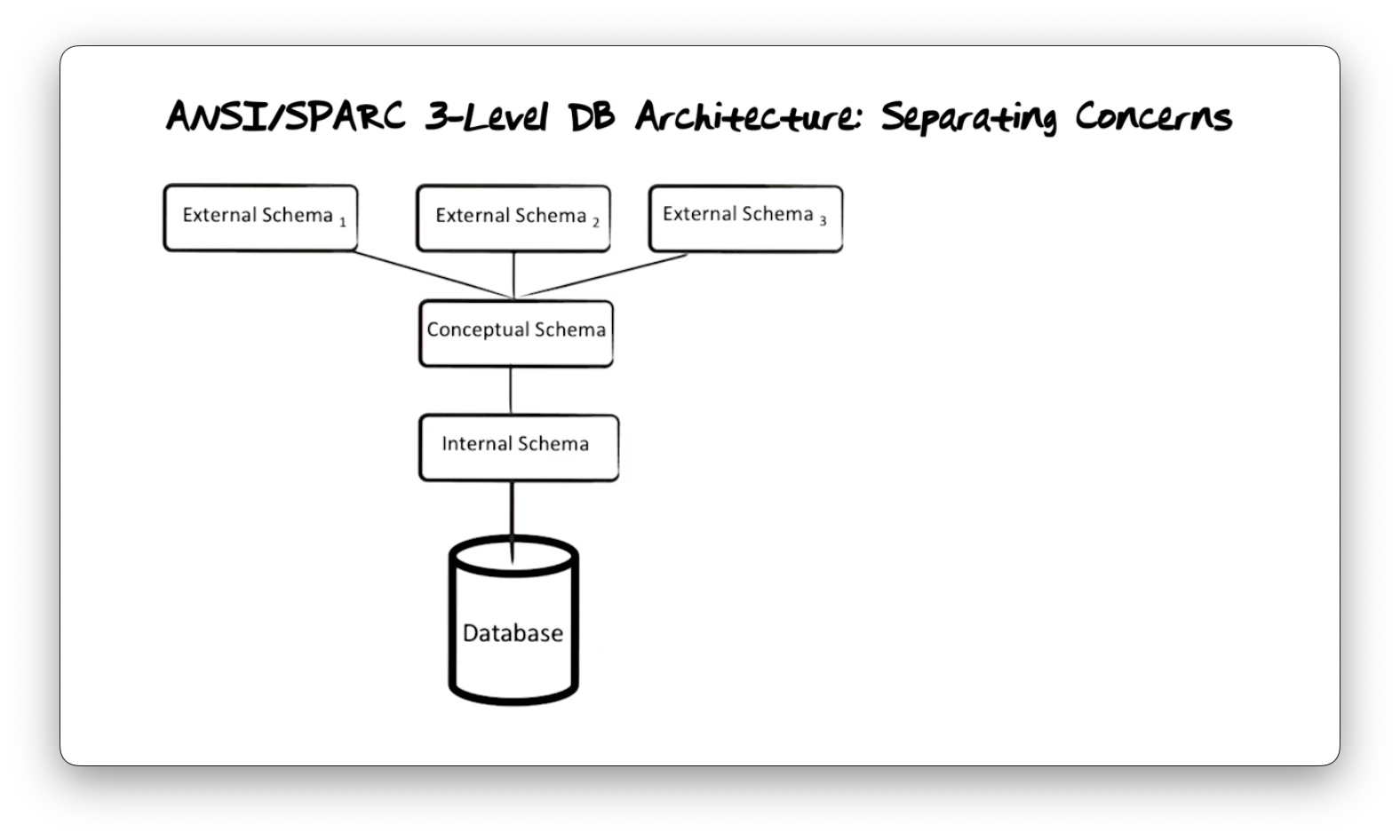
Data access sits underneath the internal schema. The database management system translates queries made against the conceptual schema into a format understood by the internal schema. Once the system retrieves the requested data from the underlying storage medium, it crafts an appropriately formatted response to send back to the user. The benefit of this approach is that it enables database systems to change the mechanisms used for database storage without affecting the applications on top.
Different applications have different needs for the data in a database. We can create multiple external schemata for slices of our database in formats that are meaningful to the applications. The system translates requests against the external schemata into requests against the conceptual schema. After data access, the system translates the response according to the external schema and presents it to the application in the appropriate format.
Conceptual Schema
The conceptual schema describes all conceptually relevant, general, and time-invariant structures of reality. It conveys nothing related to data representation, physical organization, access, or use.
Consider the following conceptual schema of the RegularUser table:
Email | BirthDate | Hometown | LastName | MaidenName | Sex | SalaryThe only thing visible to the query language at the conceptual level is this table and the columns in it. We could write the following query to fetch data from this table:
select Email, BirthDate, MaidenName
from RegularUser
where Sex='F' and Salary > 70,000We cannot express anything at this level to control how the database displays
the results (other than the ordering of columns from the select clause) or how
it accesses the underlying data.
External Schema
The external schema describes a subset of the information defined in the conceptual schema, and therefore must be logically derived from it, in a form convenient to a particular user group's needs.
We can create such an external schema from the RegularUser conceptual schema
definition using the create view statement:
create view HighPayFemales as
select Email, MaidenName, Hometown
from RegularUser
where Sex='F' and Salary > 70000
order by MaidenNameThe virtual table, or view, is named HighPayFemales and contains the
set of rows from RegularUser where values of the Sex column are 'F' and
values of the Salary column are greater than $70,000, ordered by the
MaidenName column. In some sense, a view doesn't really exist: it's just a
window into the database.
Internal Schema
An internal schema describes the physical representation of information described by the conceptual schema. The goal of the internal schema is to maximize query and update performance, and the primary data structure in use at this level is an index.
Consider the following view:
create view HighPayFemales as
select Email, MaidenName, Hometown
from RegularUser
where Sex='F' and Salary > 70000
order by MaidenNameQueries against this schema require the system to examine the Salary of every
user in the RegularUser table. If we indexed the table on Salary, the system
could retrieve the necessary users more efficiently. A B+-tree, a data
structure that enables logarithmic rather than linear data searching, is an
appropriate implementation of such an index.
Furthermore, since we are querying the Sex of each user, we may want to create
another index on Sex. In this case, the index resembles a two-column table,
where the first column contains the permitted values of Sex ('M' and 'F', in
this example), and the second column contains pointers to rows containing that
value in the Sex column of RegularUser. Using this index, all queries
against Sex can discard all rows not matching the requested value without
searching through them.
Since the applications cannot access the index, it is possible to replace index implementations or remove indexes altogether without affecting the applications above.
Physical Data Independence and Logical Data Independence
The ANSI/SPARC architecture provides two types of independence. Physical data independence describes how much we can change the internal schema of a database without affecting the applications that run on the external schemata. Logical data independence describes how much we can change the conceptual schema without changing the applications that run on the external schemata.
Database technology allows us to achieve nearly complete physical data independence. This separation is similar to the idea of encapsulation in object-oriented programming languages, whereby the implementation of the class can be changed without affecting the applications that access the class through its methods.
Logical data independence is a much loftier goal. Since the external schemata against which the applications are written are logically derived from the conceptual schema, changing a conceptual schema significantly without having to update external schemata is rare.
ANSI/SPARC DBMS Framework
Let's look at a diagram of the database components necessary to create and support a three-level architecture.
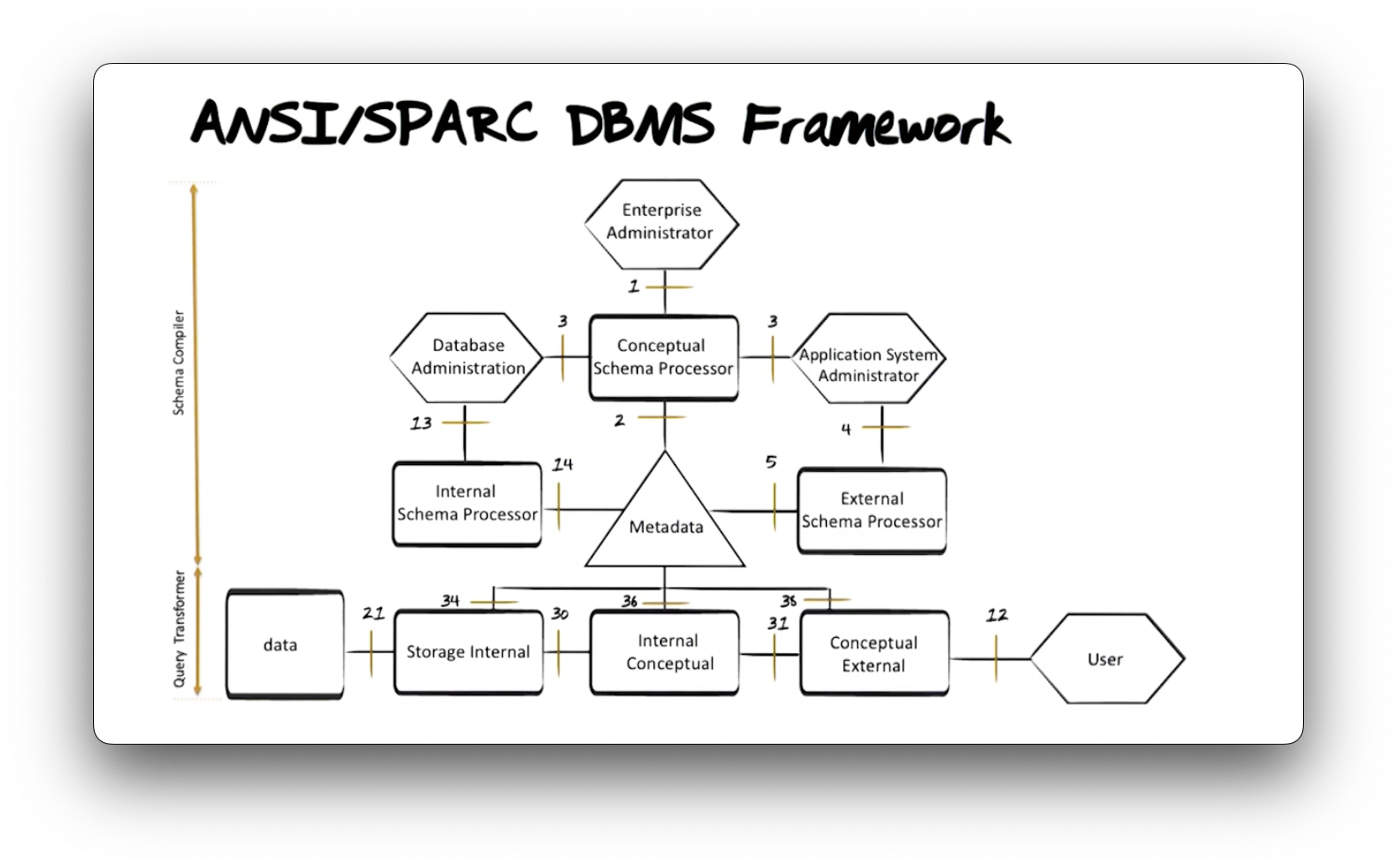
The American National Standards Institute (ANSI) proposed the framework above in 1975, before any commercial implementations of relational databases existed, which profoundly impacted how engineers built those databases.
The hexagons in the diagram represent different people in different roles within a database management system, the boxes represent processes or pieces of software that transform text, and the triangle represents the metadatabase that houses schema definitions.
The framework consists of two pieces: the schema compiler and the query transformer. Let's first talk about the schema compiler.
The enterprise administrator defines conceptual schemata using the language
interface 1 above. The conceptual schema processor checks those
definitions for correct syntax and stores the schemata in the metadatabase using
interface 2.
An application system administrator is responsible for defining external
schemata. They consume the conceptual schema using interface 3 and express
external schema definitions through interface 4. The external schema
processor checks that definition for correct syntax and stores the external
schema definition inside the metadatabase using interface 5.
A database administrator reads the conceptual schema via interface 3 and
defines an internal schema through interface interface 13. The internal
schema processor parses that definition for syntactical correctness and
ensures that it physically implements the conceptual schema and then stores that
information inside the metadatabase using interface 14.
Now let's look at the query transformer. A user expresses queries on the
database expressing the language interface 12. As we said previously, the user
can consume this interface directly via ad-hoc queries or indirectly through
some host application code that makes their queries on their behalf.
The external to conceptual transformer reads information that describes both
the conceptual and external schemata from the metadatabase using interface 38
and uses that information to translate the query expressed via interface 12
into a lower-level query expressed via interface 31.
Similarly, the conceptual to internal transformer reads both the conceptual
and internal schemata information from the metadatabase via interface 36 and
translates the incoming query from interface 31 into a query understood by
interface 30.
Finally, the internal schema to storage transformer reads the internal
schema definition from the metadatabase via interface 34 and translates the
query into operating system calls to retrieve the data from storage via
interface 21.
When the operating system returns the requested data, the database system executes the transformation process in reverse as it prepares a response to return to the user.
NB: If this process took place every time we queried the database, the system would be incredibly inefficient. The process looks slightly different in production database systems, but the overall functionality is as we just described.
Metadata Chart
Let's look at a slightly different illustration.
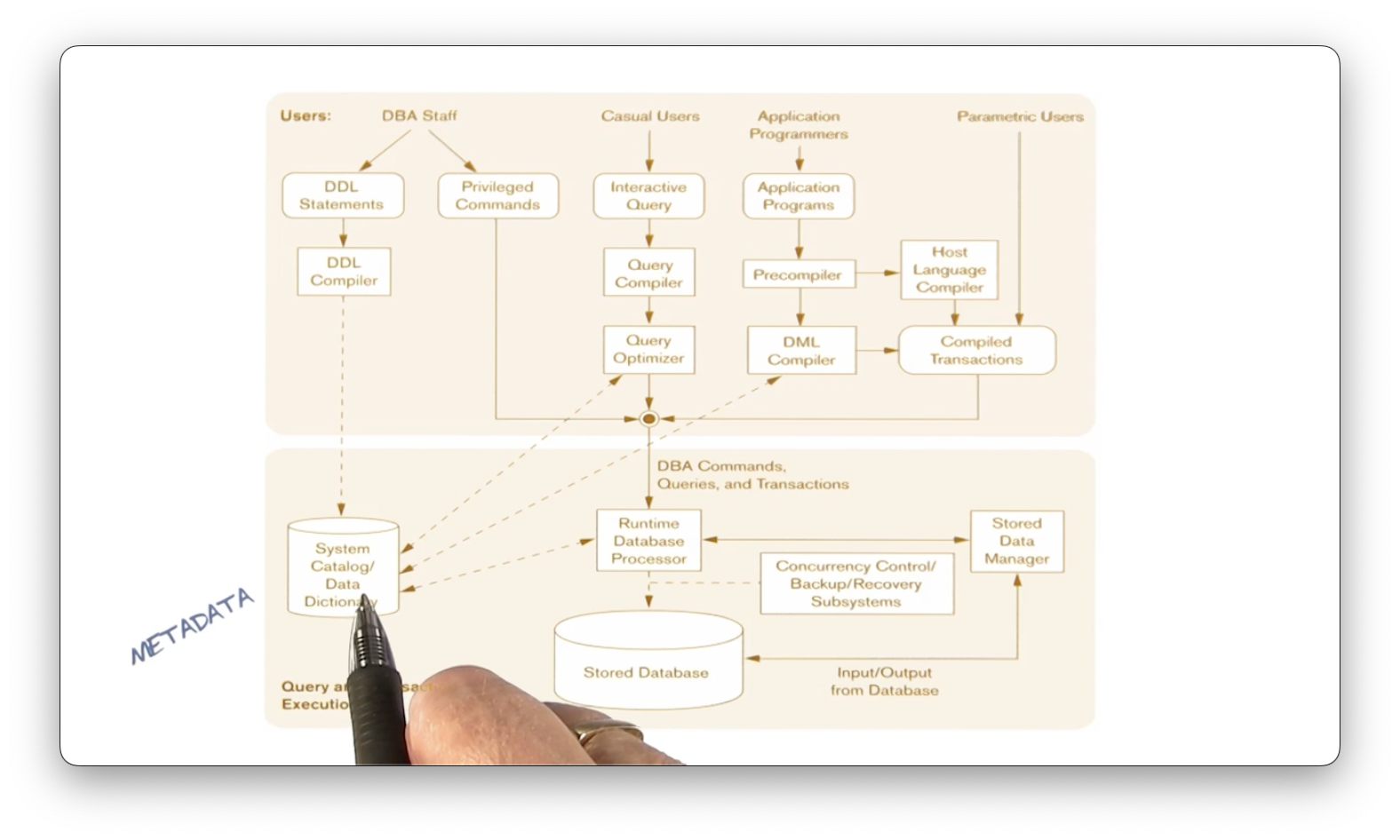
Database administration (DBA) staff includes the three human roles responsible for defining conceptual, internal, and external schemata. These individuals create those definitions using data definition language (DDL) statements, and the DDL compiler compiles those definitions and stores them in the metadatabase.
A casual user writes an interactive query compiled and optimized by the query compiler and query optimizer, respectively. After this preprocessing step, the system sends the query as a DBA command to the runtime database processor, which will execute it with other queries on the database.
Application programmers write programs consisting of host language code with embedded database access. The precompiler receives that code, out of which comes the host language code and the database manipulation statements. These components have their respective compilers, and the compilation outputs combine into a compiled transaction that the runtime database processor receives and executes against the database.
Since there may be many concurrent users querying the database, a concurrency control subsystem ensures that the runtime processor executes the competing transactions on the database in the proper order.
Metadata - What is It?
There are two types of metadata: system metadata and business metadata.
System metadata answers the following questions:
- Where did data come from?
- How has data changed?
- How is data stored?
- How is data mapped?
- Who owns the data?
- Who can access the data?
Systems metadata also provides information on data usage history and statistics. Systems metadata is critical for a database management system to function correctly.
Business metadata answers the following questions:
- What data is available?
- Where is the data located?
- What does the data mean?
- How can I access the data?
- How current is the data?
Additionally, business metadata can also provide information about predefined reports and queries. Business metadata is critical for business. For example, data warehouse applications cannot run without business metadata. Later in this course, we will discuss metadata and its use in data archival.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy