Databases
Relational Algebra and Calculus
24 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Relational Algebra and Calculus
Closed Algebra
Let's talk about closed algebra. Consider the following expression containing rational numbers:
Even if we can't discern the result by looking at the expression, we know the steps required to compute the result based on the rules governing the order of operations.
We call this algebra closed because each expression involving rational numbers evaluates to a rational number, resolving to the same type of data as we input. A closed algebra allows you to formulate high-level models and use previous thoughts to form new ones. In the expression above, we build up intermediate results from the initial operands until we finally arrive at one value.
Relational Algebra Operations
Let's look at a collection of relational algebra operators involving two relations, , and . First, we have four set operators:
- The set union operator,
- The set intersection operator,
- The set difference operator,
- The Cartesian product operator,
We use the projection operator, , to eliminate attributes, or columns, from a relation. For example, selects only those attributes in . We use the selection operator , which eliminates rows. For example, selects only those rows in for which evaluates to true.
The third group of operators is the joins, which are constructor operations. We have the natural join operator, . We also have outer joins, of which there are three types: right, left, and full. In this lesson, we look at left outer joins, . Finally, we have theta joins, .
In the last group of operators, we see the division operator, , and the rename operator, . Division in relational algebra provides functionality similar to universal quantification in relational calculus. The rename operator lets us rename relation attribute names so two relations can have the same name for certain attributes and thus be joined on them.
The symbol for the left outer join is not really . It's the symbol shown in the lectures. Unfortunately, it's not in my character set in this environment, so I can't express it.
Selection
The general syntax to select all the tuples from a relation, , that satisfy
an expression is . For example, if we want to
retrieve all tuples in the RegularUser relation, we would say:
If RegularUser has tuples, the resulting relation after running this query
will also have tuples in it because we haven't specified any condition to
eliminate tuples.
Selection - Simple Expression
Let's look at the selection operator with a simple expression. Suppose we want to find all regular users whose hometown is Atlanta. We can express that query in relational algebra as:
We can form simple expressions in one of two ways: either we can compare two attributes or an attribute to a constant. The comparison operators we have at hand are , , , , , and .
In the RegularUser table, we now select all tuples with a value of 'Atlanta'
for the HomeTown attribute. Remember, when we perform a selection, we retain
the number of columns from the original relation in the selection result.

Selection - Composite Expression
Suppose we want to find all regular users with the same current city and hometown or with a hometown of Atlanta. We can express this query as so:
Notice that the result of this selection, shown below, includes users who have a hometown in Atlanta and those whose hometown matches their current city. For example, we see one user from Dallas who currently lives in Dallas and another user from Austin who currently lives in Austin.

We can form composite expressions by combining simple expressions. Conjunction, expressed mathematically as , refers to 'AND'ing two expressions, disjunction, , refers to 'OR'ing them, and negation refers to inverting the truthiness of an expression. Additionally, we can place parenthesis around an expression, which gives us fine control over the order of operations.
Projection
Given a relation, , and attributes, , where forms a subset of the attributes on , we can project from like so:
For example, suppose we want to retrieve just the email, birth year, and sex for all regular users in Atlanta. We can express this query with the following syntax:
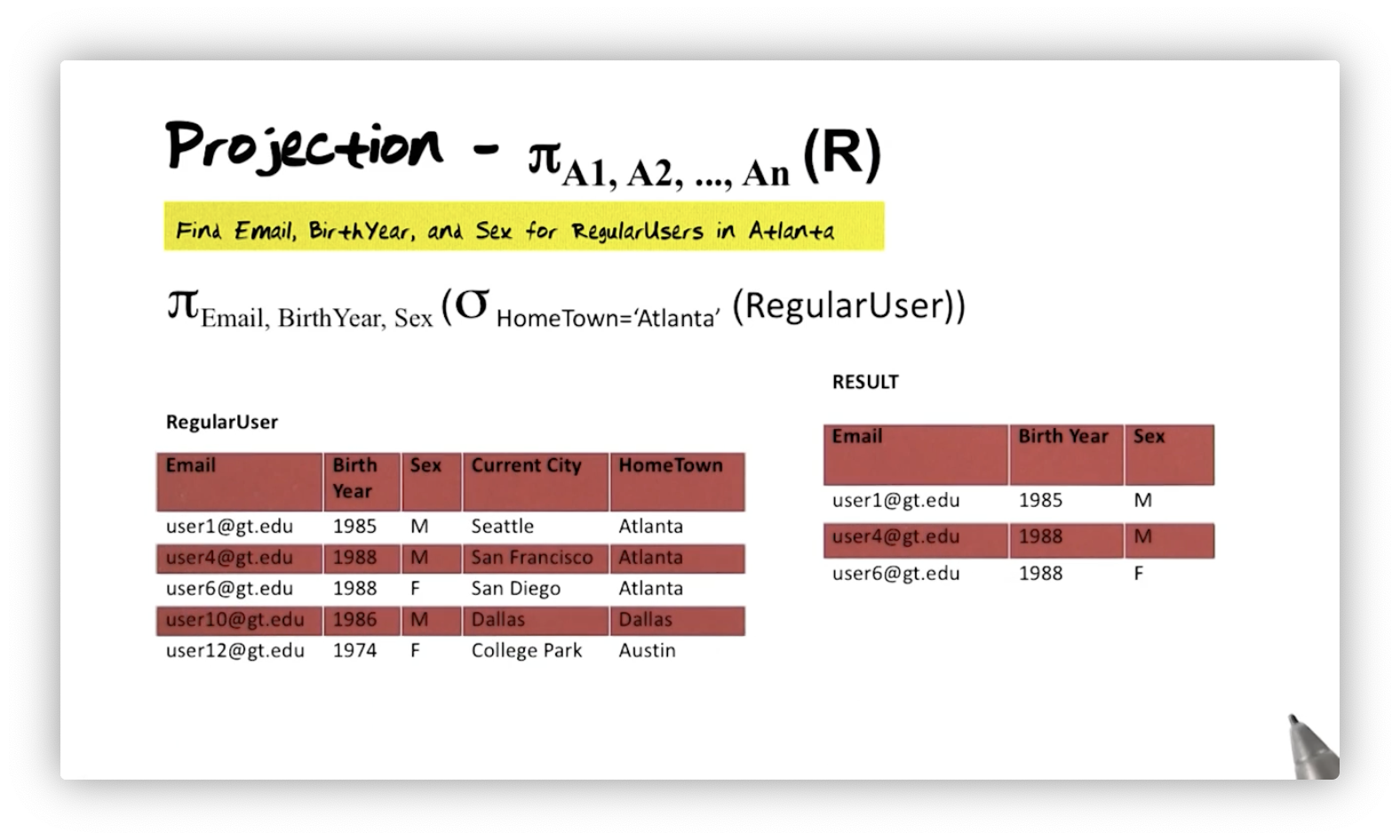
This query demonstrates the power inherent in relational algebra being a closed
query language. First, we take the RegularUser relation and perform a
selection. From that intermediate result, which we know must be a relation, we
can then perform the projection. We can only express composed queries like this
when working with a closed algebra.
Relations are Sets
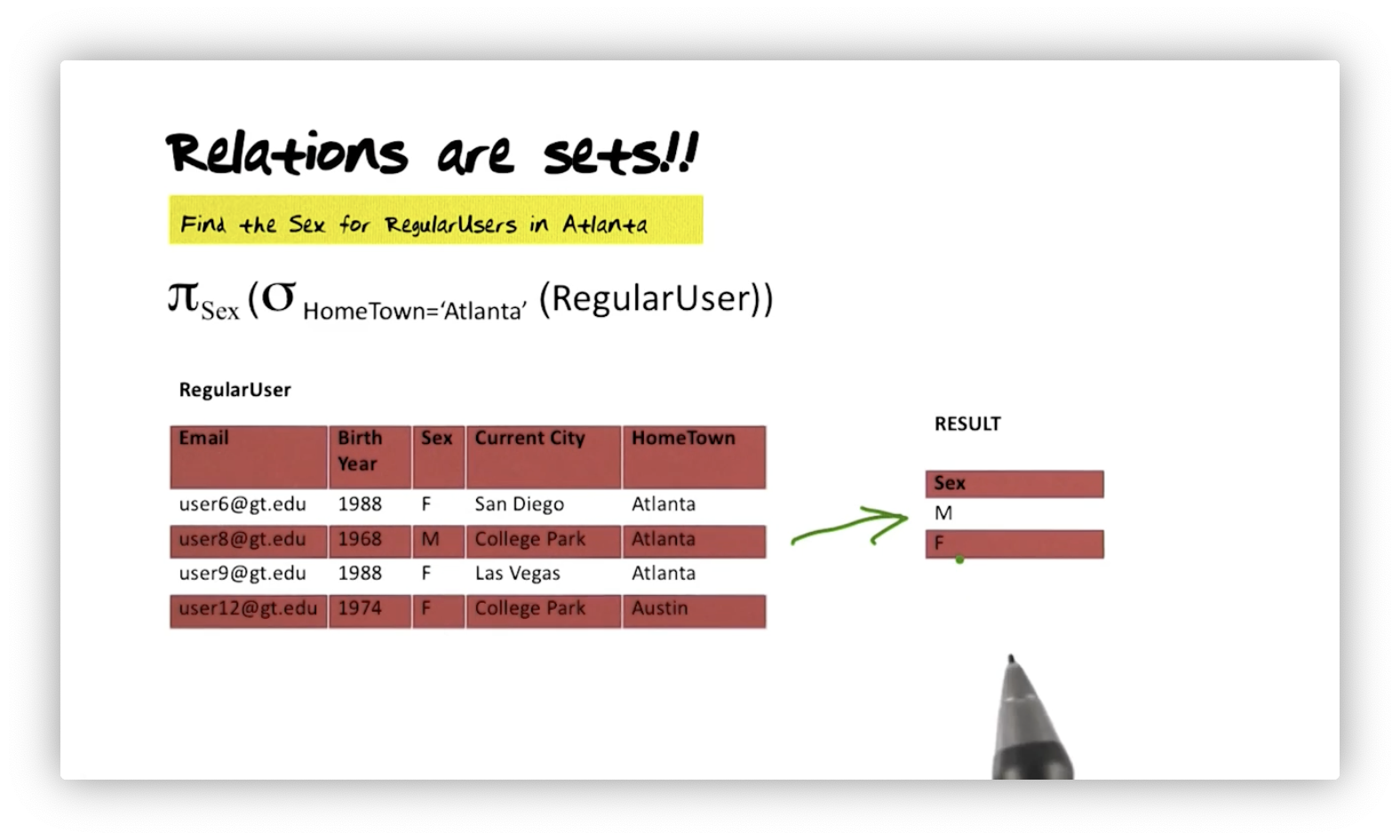
Let's say we want to find the sex of regular users in Atlanta. We could specify that query as:
In the RegularUser table, we have three users from Atlanta, so we have three
tuples that match our selection condition. Our projection, however, only shows
one "M" and one "F", despite the selection returning two females and one male.
In other words, relations are sets and, thus, do not contain duplicate tuples.
Intersection
The second set-based operator is the intersection operator: . For example, consider the set of cities that are hometowns and the set that are current cities for regular users. We can find the elements that those sets share with the following query:
In the RegularUser relation, we see Dallas and San Francisco appear in both
the CurrentCity and HomeTown columns, so those values constitute our result.

Set Difference
The third set-based operator is the difference operator, . Suppose we want to find the elements of the set of current cities that are not also elements of the set of hometowns. Here's how we would formulate this query:
Of the cities in the CurrentCity column, only Dallas is in the HomeTown
column. Thus, we eliminate it from the result. Notice again that we drop
duplicate values; College Park appears as a current city twice in RegularUser,
but only once in the result.

Natural Join
Let's say we want to generate a relation that displays user and event
information for every year an event occurred and a user was born. Suppose we
have two relations: RegularUser, with attributes Email, Year, and Sex;
and Major60sEvent, with attributes Year and Event. We need to join the two
relations to answer this query, and we formalize this natural join as
follows:

Notice that both RegularUser and Major60sEvents have a similarly named
attribute, Year. The natural join operation compares all combinations of
tuples from both relations and checks if the value of Year is the same.
If a tuple in either relation has a value of Year that is not present in the
other, then that tuple will be absent from the result. In the joined relation,
all attributes from the constituent relations are present, with the joined
attribute appearing once. If multiple tuples have matching attributes, we will
see one tuple in the join relation for each match.
Let's summarize some of the features of a natural join:
- It matches values of attributes with the same name and only those.
- It keeps only one copy of the join attribute in the result.
- We call a natural join an inner joinbecause only the matching tuples appear in the result, with unmatched tuples eliminated.
Theta Join
Next, we look at the theta join. Suppose we want to find the email, birth year, sex, and event year when the birth year of the regular user occurs before the year of the major 60s event. We can formalize this query as follows:
In the result, we see one user born in 1967 predates four events, while another user born in 1968 predates one. Notice that the resulting relation has five rows, not two. Our result has a row for each user/event combination.

Let's compare the natural join with the theta join:
- A natural join can express only equality conditions, while a theta join can also express inequality conditions using the , , , , and operators.
- Two relations joined by a natural join must share an attribute name, while the theta join does not have this restriction.
- In the natural join, the join attribute appears once in the result. Both
attributes in a theta join appear in the relation (
BirthYearandEventYearabove).
Like a natural join, a theta join preserves all attributes from the joined relations in the result. The theta join is also an inner join because tuples in the two relations that do not match each other do not appear in the result.
Left Outer Join
The third constructor operator we examine is the outer join operator,
specifically the left outer join, whose operator is .
Suppose we want to perform the natural join we saw above and retain unmatched
tuples from RegularUser. The algebra expression is:
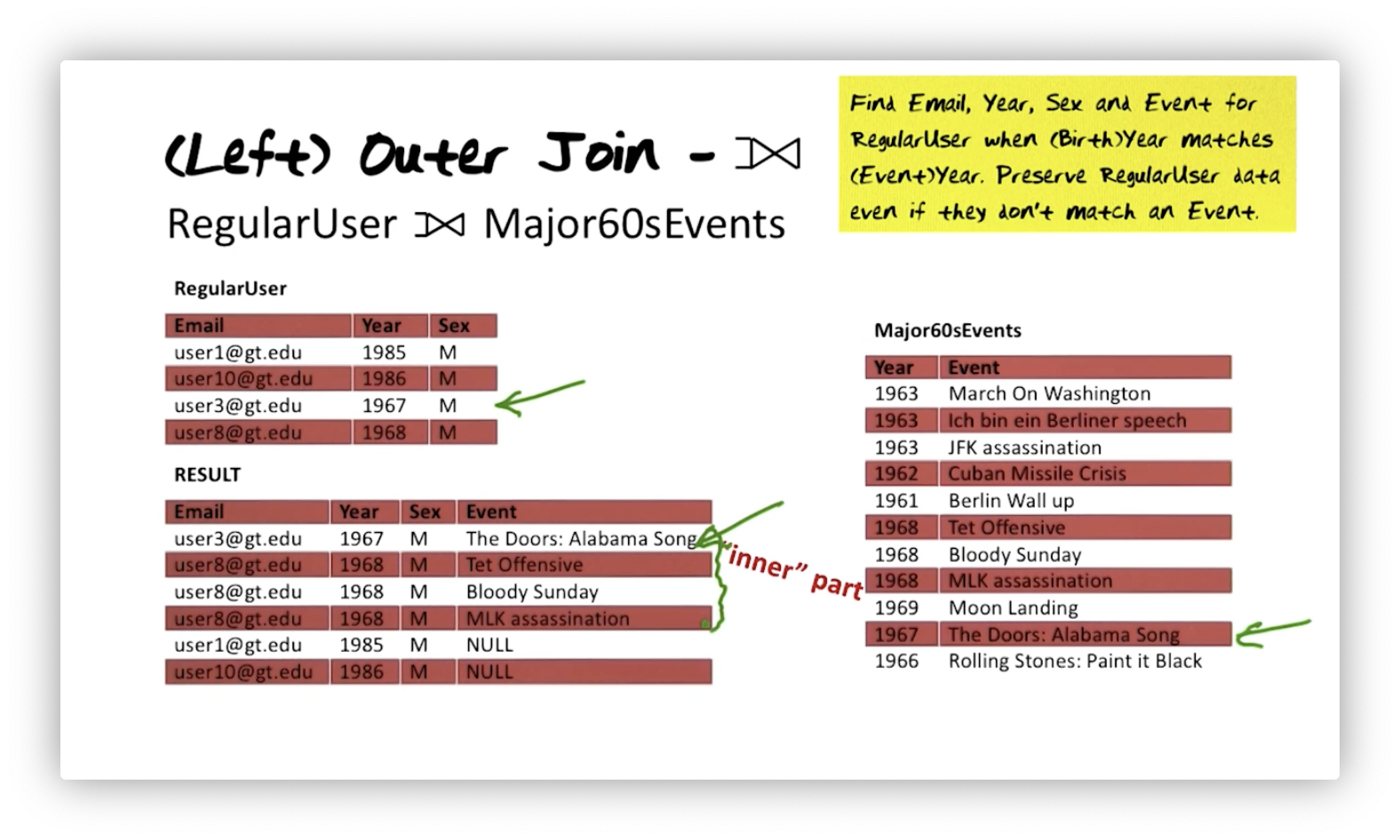
For every user whose birth year matches the event year, we include a tuple for
every match. Two users' birth years don't match any event year in the events
table. We said we want to retain their information, and we can include it, but
we must fill in the absent event information with NULL values. That NULL
corresponds to the "outer" part of the result.
The resulting relation is a superset of the result of the natural join we expressed earlier. In this case, the left outer join we saw here is a natural left outer join - a special case of the natural join - because we compared attributes of the same name.
Cartesian Product: X
The fourth constructor operator in the relational algebra is the Cartesian
product operator, . A Cartesian product, , results in a
relation with tuples, where is the number of tuples in , and
is the number of tuples in . For example, we can combine every tuple in
RegularUser with every tuple in UserInterests:

There are no comparison rules in the Cartesian product - in contrast to the other joins - to selectively include only certain matches in the result. Here, we combine everything. Why might that be useful?
Cartesian Product: Can be Useful
Suppose we have a RegularUser relation and a UserInterests relation. The
UserInterests table contains information about users' interests and has a
foreign key, Email, that references the primary key in RegularUser. We want
to find all the hobbies in which each user has not expressed interest.
First, we project RegularUser onto Email and UserInterests onto Interest
so that we have one relation containing just user emails and another with just
user interests. Now, we compute the Cartesian product of the two results, which
creates a tuple for each user for each interest. Finally, we subtract from this
result UserInterests to eliminate the interests we already recorded. We
express this query as:
Notice that the two operands in the set difference are compatible. The resulting
relation from the Cartesian product operation has Email and Interest
attributes, and from that, we subtract the projection of UserInterests onto
Email and Interest (dropping Since Age).
Here is the result. Let's look at user one, for example. In UserInterests,
this user has music as an interest but not blogging or meditation. We see those
two hobbies associated with this user in the result.

Divide By
Now let's look at the divide by algebra operator: . This operator plays the same role in relational algebra as universal quantification in relational calculus. Suppose we want to find the email of all users with at least all the interests of user one.

User one has three interests: music, reading, and tennis. User one has at least as many interests as user one, so we include them in the result. User three has all of the interests of user one plus more, so we include them in the result too. Neither user two nor user four have at least the set of interests that user one has, so they are absent from the result.
Here's how we perform the divide-by operation. First, we calculate the divisor
by projecting UserInterest onto Email and Interest. Then, we calculate the
dividend by selecting user one's interests from UserInterest and then
projecting that relation onto Interest. The result is a single-column relation
containing music, reading, and tennis. We can express this query in the algebra
like so:
When we divide one relation by another, the divisor has attributes and , the dividend has attribute , and the result has attribute . We divide by to produce here. The divide by operation always follows this structure.
Here is formal definition of the result where is the RegularUser
relation, is the intermediate projection of user one's interests,
is short for "Email" and is short for "Interest":
What this formalism describes is the following. Let's look at each candidate tuple in relation . For all () tuples in relation , if there exists () a tuple in such that and have the same email and and have the same interest, then include in the result.
Rename
The last algebraic operator we examine is the rename operator, . Renaming attributes and relations is useful when we want to perform various types of joins. Here is the basic syntax:
For example, we can rename the RegularUser relation to RUser, the
BirthYear attribute to Year, and the Sex attribute to Gender:

Relational Calculus
Relational algebra is procedural; we combine operators to describe the steps we must take to produce the desired result. For instance, we might say join two relations, project the result, and then select from that result to get the final relation. Relational calculus is declarative. Instead of describing steps, we describe the result we want. Relational tuple calculus forms the basis of SQL.
One might think that tuple calculus has more expressive power than algebra. As it turns out, both can be shown to be equivalent regarding data retrieval "horsepower", as Professor Mark calls it.
Relational Calculus Expressions
Let's look at expressions in relational calculus - specifically relational tuple calculus, so named because queries have variables that range over sets of tuples. Here's a query:
This query returns the set of tuples that satisfy the predicate . Predicates consist of atoms, so let's first define the atoms in this calculus.
The first atom is the range expression. For example, , and denote that is a tuple of relation . The second atom compares two tuple attributes. We reference tuple attributes as follows: denotes the value of attribute on tuple . The third atom compares a tuple attribute to a constant, . We use to denote comparison operators, which consist of , , , , and .
In summary, atoms are one of the following:
- A range expression:
- A comparison of two attributes:
- A comparison of one attribute and a constant: .
An atom is a predicate. Furthermore, given atoms and , the following expressions are also predicates: , , , , and , where means "implies".
Finally, if is a predicate and is a free variable in , and is a relation, then "there exists a in that satisfies " is a predicate called the existential quantifier: . Likewise, "for all in for which is true" a predicate called the universal quantifier: . If is free in the predicate , then using the existential quantifier or the universal quantifier binds .
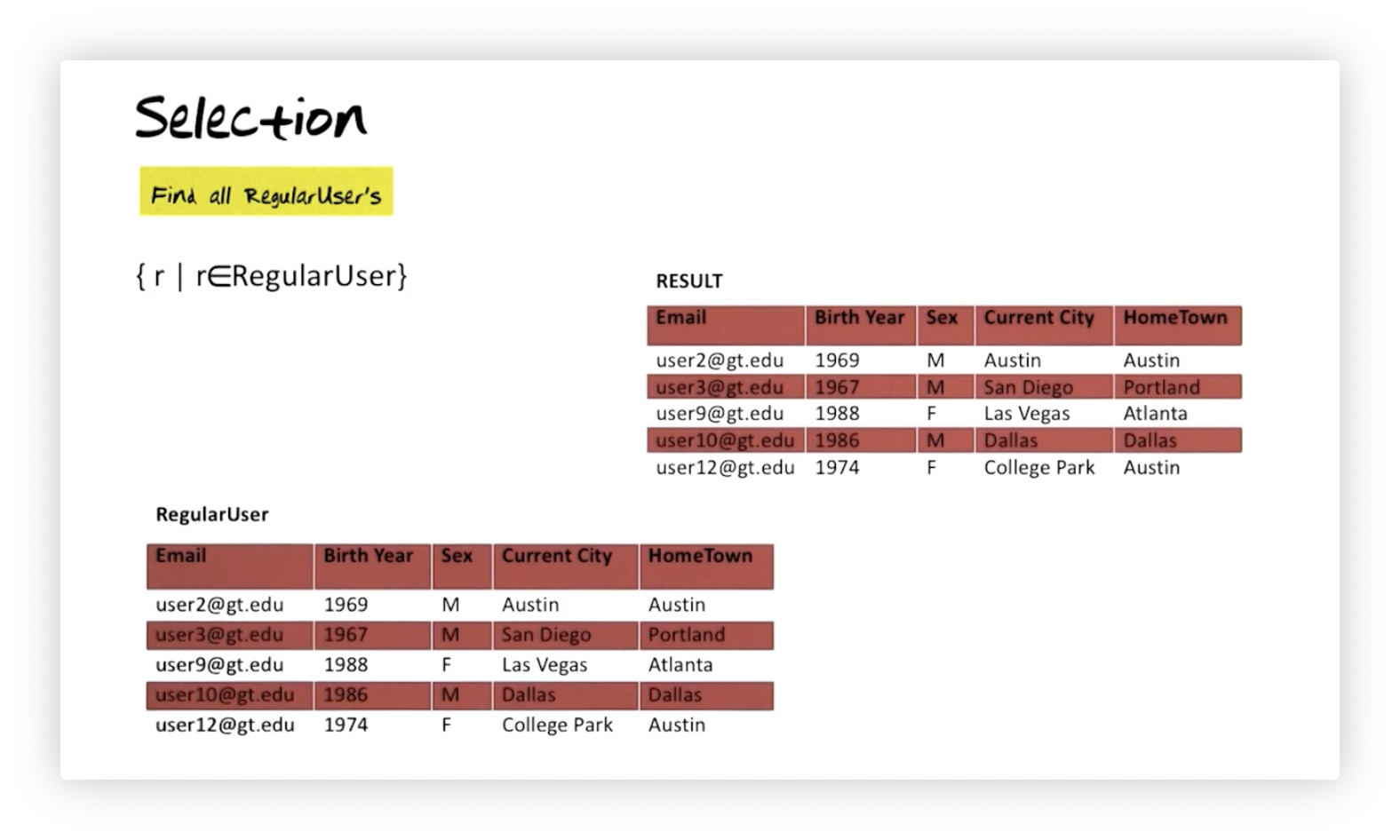
Calculus - Selection
For the rest of the lectures in this section, we will revisit the queries we saw in the relational algebra section and express them using relational tuple calculus. Here is the corresponding tuple calculus expression for selecting all regular users:
We can think of this query as: find the set where is a member of the relation . As we might expect, this relation is identical to .
Calculus - Selection: Composite Expression
Let's find all regular users who have the same current city and hometown or have a hometown of Atlanta:
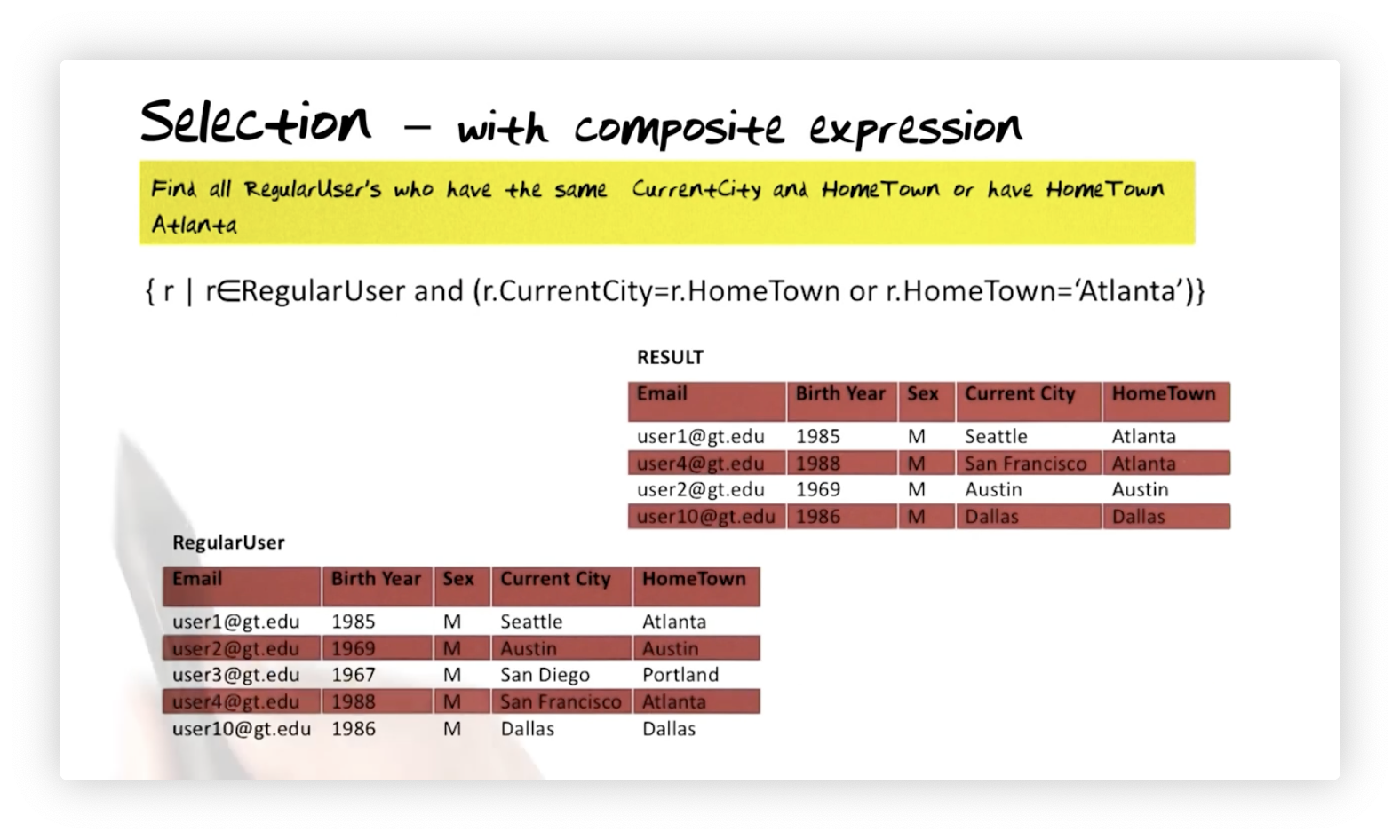
Notice that even if we had another relation with the attributes CurrentCity
and HomeTown with similar values, those tuples would be absent from the result
because they did not come from . All expressions in the
selection query must be true for a tuple to appear in the result.
Calculus - Projection
Suppose we want to find the email, birth year, and sex for all regular users whose hometown is Atlanta. Here is that query:
We can see below that the resulting relation consists of only the requested attributes for the tuples that match the selection query.
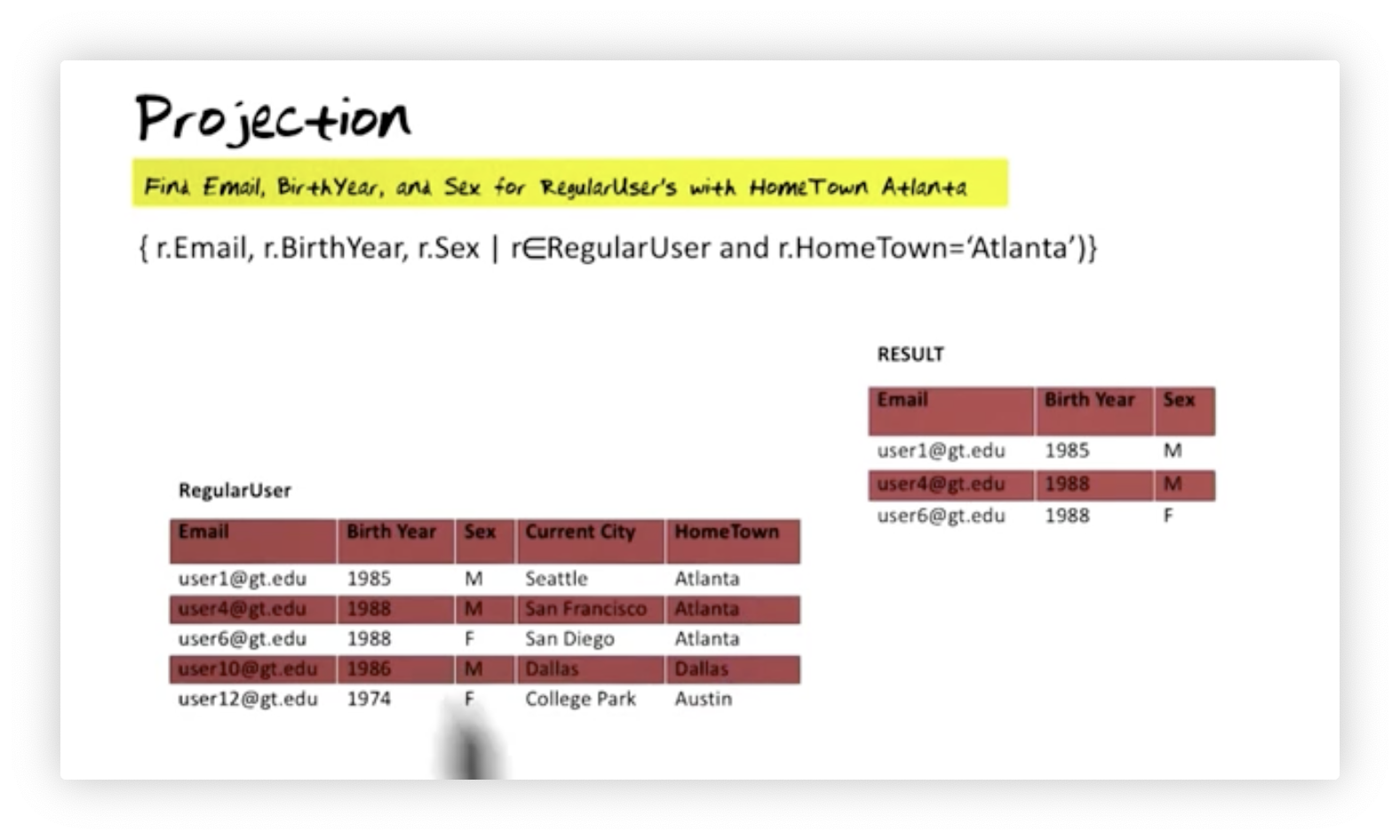
Calculus - Union
Let's find all cities that are either a current city or a hometown for a regular user.
If a tuple exists in with a current city, then that city is part of the result. Similarly, if a tuple exists in with a hometown, then that city is part of the result.

Calculus - Intersection
Let's find all cities that are a current city for some regular user and a hometown for some regular user.
For a tuple to qualify, there must exist a tuple in that has the same city as , and it must also be the case that there is a tuple that has the same hometown as . We retrieve the attribute for qualifying tuples.

Calculus - Set Difference
Suppose we want to find the elements of the set of current cities that are not also elements of the set of hometowns. Here's how we would formulate this query:
For a tuple to qualify, there must exist a tuple in that has the same city as , and it must also be the case that there is not a tuple that has the same hometown as . We retrieve the attribute for qualifying tuples.

Calculus - Natural Join
Let's say we want to generate a relation that displays user and event information for every year an event occurred and a user was born. Suppose we have two relations: , with attributes , , and ; and , with attributes and . We need to join the two relations to answer this query, and we formalize this natural join as follows:

Let's decipher this query expression. We are interested in a tuple, that contains , , , and attributes. What must be true for us to include in the result? Well, there must exist a tuple in and a tuple in . If equals , then we pick , , , and into and include it in the result.
Calculus - Cartesian Product
Let's say we want to combine every tuple in the relation with every tuple in the relation. We can express that Cartesian product in relational calculus like so:

Calculus - Cartesian Product: Can be useful
Suppose we have a relation and a relation. The table contains information about users' interests and has a foreign key, , that references the primary key in . We want to find all the hobbies in which each user has not expressed interest. Here is how we express this query:

We are looking for a tuple, , from and a tuple, , from where it is not the case that there exists a tuple, , from that has the same as or the same as . We then select and for those tuples and for which this predicate is true.
Calculus - Divide By
Suppose we want to find the email of all users with at least all the interests of user one. Here is how we express that query in relational calculus:
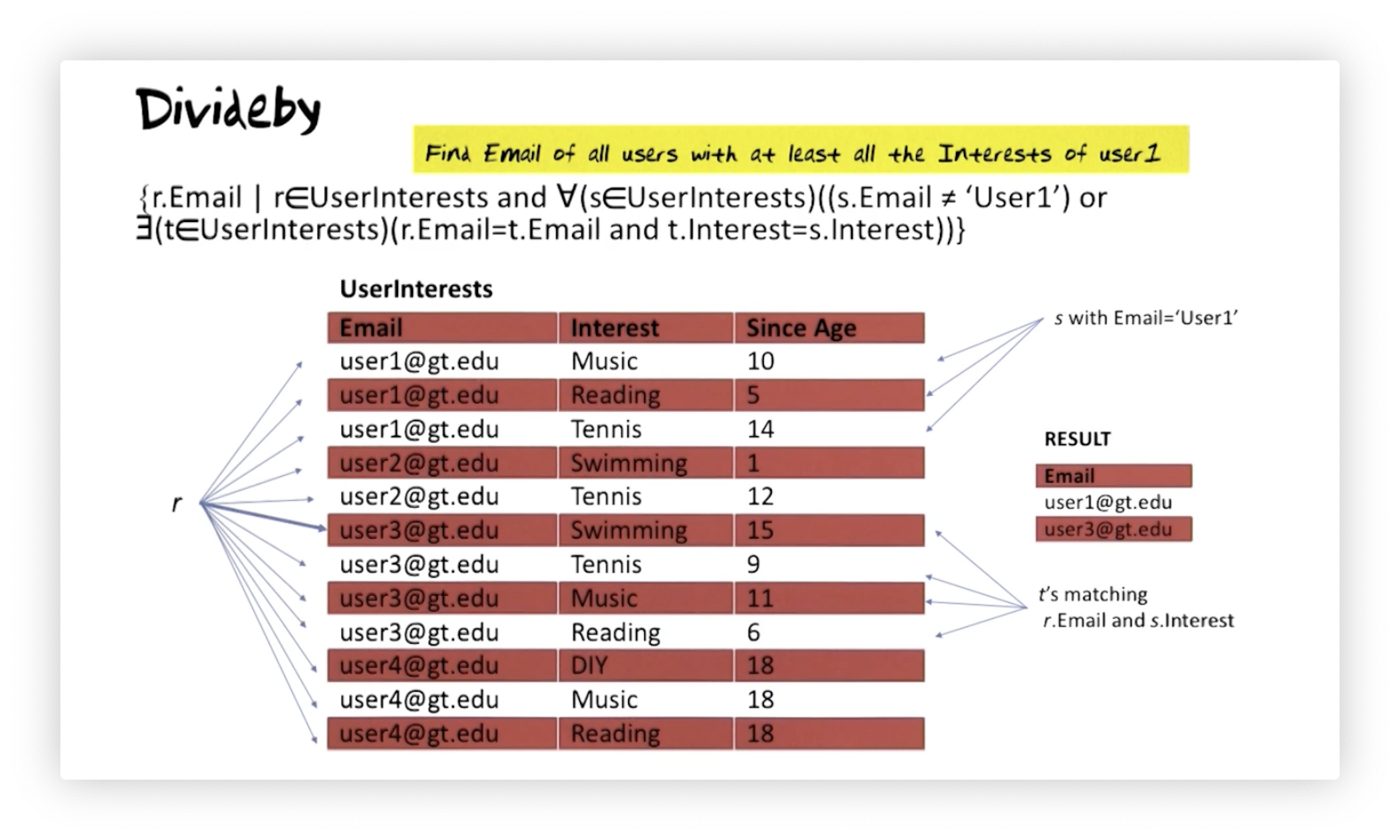
We are interested in values of the attribute on tuples from the relation. For a candidate tuple, we must check that something is true for every tuple in . Either the value of the attribute for must not be user one's email address, or, if it is, then the following must be true: there must exist a tuple in that shares an email with and an interest with .
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy