Computer Networks Old
Internet Worms
7 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Internet Worms
Types of Viruses and Worm Overview
A virus is an "infection" of an existing program that results in the modification of the original program's behavior.
A worm is code that propagates and replicates itself across the network.
Types of viruses
A parasitic virus typically infects an existing executable file.
A memory-resident virus infects running programs.
A boot-sector virus spreads whenever the system is booted.
A polymorphic virus encrypts part of the virus program using a randomly generated key.
Viruses vs. Worms
One of the key differences between viruses and worms is in how they propagate.
Viruses typically spread with manual user intervention; for example, by opening an email attachment or plugging in a USB drive.
Worms typically spread automatically by scanning for vulnerabilities and infecting vulnerable hosts when those vulnerabilities are discovered.
Internet Worm Lifecycle
Once a worm infects a host, that host will first scan other machines on the internet to discover vulnerable hosts, and will then infect those hosts via remote exploit.
First Worm: "Morris" Worm
The first worm - the Morris Worm - was designed by Robert Morris in 1988.
The worm itself had no malicious payload, but it ended up bogging down the machines it infected by spawning new processes uncontrollably and exhausting resources.
At the time it was released, it infected 10% of all internet hosts.
It spread through three different propagation vectors.
First, the worm tried to crack passwords using a small dictionary and a publicly readable password file. In addition, it also targeted hosts that were already listed in a trusted hosts file on the infected machine.
The second way that it spread was through a buffer overflow vulnerability in the finger daemon.
The third way that it spread was through the debug command in sendmail. In early sendmail versions it was possible to execute a command on a remote machine by sending an SMTP message. The worm used this feature to spread automatically.
A common theme along the design of worms is the idea of multiple propagation vectors, which allows the worm to have more ways to spread and often speeds up the propagation of the worm.
The Morris Worm highlights the general approach to worm infection and propagation.
First, the worm has to scan other machines on the network to find more potential vulnerable hosts. Next, the worm has to spread by infecting other vulnerable hosts. Finally, the worm should remain undiscoverable so that it can continue to operate and spread without being removed from systems.
Worm Outbreak in Detail
The summer of 2001 saw three major worm outbreaks: Code Red 1 v2, Code Red 2, and Nimda.
Code Red 1
Code Red 1 - the first "modern" worm - was released on July 13, 2001. This worm exploited a buffer overflow in Microsoft's IIS server.
From the 1st through the 20th of each month, the worm would spawn 99 threads which generated IP addresses at random, and would then look for vulnerable instances of IIS on the hosts at those IP addresses. If the vulnerability was found, the worm would spread to that host.
Version 2 of Code Red 1 was released six days later and fixed the random scanning bug. In this version, each instance of the worm would scan a different part of IP address space.
After the scanning bug was fixed, the worm was able to compromise 350k hosts in only 14 hours. By most estimates, that was the complete set of hosts running the vulnerable version of IIS on the entire internet.
The payload of this worm was to mount a denial of service attack on whitehouse.gov, but a bug in the worm's software caused it to die on the 20th of each month. If the victim's clock was wrong, however, the worm would resurrect itself on the 1st.
Fortunately in this case, the denial of service attack launched at whitehouse.gov was actually launched at a particular IP address instead of the domain name. The operators of the website needed only to move the web server to a different IP address to defend against the DoS attack.
Code Red 2
Code Red 2 - released on August 4, 2001 - exploited the same vulnerability, but had a completely different payload.
The worm only spread on Windows 2000, crashing on Window NT.
The scan preferred nearby addresses, choosing addresses from the same /8 subnet with probability ½, from the same /16 with probability ⅜, and randomly from the entire internet with the remaining ⅛ probability.
The reason for preferring nearby addresses was that if there was one vulnerable host on the network, there was likely to be more because the same administrator that failed to patch the compromised machine likely failed to patch other machines on their network.
This notion of preferential scanning can speed up infections in some cases by increasing the probability that scanning will find another vulnerable host.
The payload of this worm was an IIS backdoor and was completely dead by design by October 1, 2001.
Nimda
Nimda - released on September 18, 2001 - spread through multiple propagation vectors, in addition to using the same IIS vulnerability as Code Red 1 and 2.
Nimda could spread via bulk email as an attachment. It copied itself across network shares. It installed an exploit code on webpages served by the web server running on the machine so that any browser that visited that webpage would become infected. It also scanned for the Code Red 2 backdoors.
The interesting thing about the multimodal nature of the nimda worm is that signature-based defenses don't necessarily help.
For example, most of the firewalls passed the emails carrying nimda completely untouched. It was a brand new infection with an unknown signature, so scanners couldn't detect it.
This was the first instance of a worm that exploited a zero-day attack, which is when a worm first appears in the wild and the signature of the worm is not extracted until minutes or hours later.
Zero-day attacks are particular virulent because the worm can spread extremely quickly before any type of signature-based antivirus has a change to catch up and begin preventing the infections.
Modeling Fast-Spreading Worms
Here is a plot showing the infection rate of the Code Red 1 v2 worm, which ultimately infected 350k vulnerable hosts.
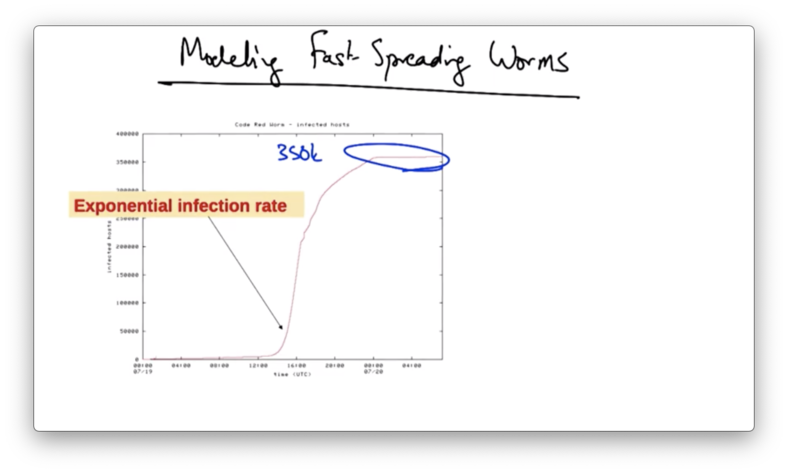
The worm is effectively dormant, or at least spreading very slowly, for quite a period of time. Then there is an inflection point, at which point the infection rate becomes exponential. At some later point infections slow, and the infection rate ultimately plateaus, presumably after all the infected hosts have been found.
We can model the spread of these worms using the random constant spread model.
Let's assume that K is the initial compromise rate, N is the number of vulnerable hosts, and a is the fraction of hosts that are already compromised.
We can use these parameters to express the number of hosts infected in a particular timeslice.
For a given timeslice dt, the number of hosts infected da * N is equal to the current number of hosts infected N * a, times the new fraction of infected hosts in that timeslice: K * (1-a) * dt.
Thus: Nda = Na * K(1-a)dt
Solving for a yields an exponential expression that depends only on K, the initial compromise rate.
This tells us that if we want to design a very fast spreading worm, then we should design it such that the initial compromise rate is as high as possible.
Increasing Compromise Rate
One possible way to increase the initial compromise rate is to create a hit list, or list of vulnerable hosts ahead of time.
From this infection curve, we can see that the time to infect the first ten thousand hosts dominates the total infection time.
If we start by performing stealthy scans to construct a list of vulnerable hosts before we start spreading, then we can get rid of that initial flat part of the curve where the worm is effectively dormant.
The second approach is to use permutation scanning whereby every compromised host has a shared permutation of an IP address list to scan for vulnerabilities.
If the list is randomly permuted and a particular host starts scanning from its own IP address in the list and works down, different infected hosts will start scanning from different parts of the list, ensuring that compromised hosts don't duplicate each other's work.
One worm that exploited these techniques to spread particularly quickly was the Slammer worm, which spread in January of 2003, exploiting a buffer overflow in Microsoft's SQL server.
In addition to using fast scanning techniques, the entire Slammer code fit into a single UDP packet. The UDP packet contained the worm binary followed by an overflow pointer back to itself.
Once the control was passed to the worm code, it randomly generated IP addresses and attempted to send a copy of itself to port 1434 on other hosts.
Since the Slammer worm was spread via a single UDP packet, the transmission of the worm was connectionless; that is, the transmission was not limited by the latency of network round trip time, but rather only by the bandwidth of the network.
The majority of the damage from Slammer was inflicted in just 30 minutes.
The worm caused $1.2 billion in damage and temporarily knocked out many elements of critical infrastructure, including:
- Bank of America's ATM network
- A cellphone network in South Korea
- Five root DNS servers
- Continental Airlines ticket processing software
While the worm did not have a malicious payload, the bandwidth exhaustion on the network caused resource exhaustion on the infected machines.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy