Computer Networks Old
Programming SDNs
15 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Programming SDNs
Updates in Software Defined Networks
In the last lesson, we looked at how to update switch flow table entries using OpenFlow control commands from the controller.
The OpenFlow API does not provide any guarantees about the level of consistency that packets experience along an end-to-end path.
For example, updates to multiple switches along a path in a network that occur at different times may result in problems such as forwarding loops. This is a packet-level consistency problem.
Additionally, if updates to switches along an end-to-end path occur in the middle of a flow, packets from the same flow may be subjected to two different network states. This is a flow-level consistency problem.
To think about consistency properly, we first need a notion of a high-level programming model that sits on top of the controller interface.
SDN Programming Introduction
The first step that a controller needs to take is to read and monitor network state as well as respond to various events that may be occurring in the network.
These events may include
- failures
- topology changes
- security events
The second step is to compute the policy based on the state that the controller sees from the network.
The third step is to write policy back to the switches by installing the appropriate flow table state into the switches.
Consistency problems can arise in two steps.
First, the controller can read state from the network switches at different times, resulting in an inconsistent view of the network-wide state.
Second, the controller may be writing policy as traffic is actively flowing through the network. This can disrupt packets along an end-to-end path, and may cause problems for packets that should be treated consistently because they are part of the same flow.
Both reading and writing network state can be challenging because OpenFlow rules are simple match-action predicates, so it can be very difficult to express complex logic with these rules.
If we want to read state that requires multiple rules, expressing a policy that allows us to read such a state can be complicated without more sophisticated predicates.
Example
Lets suppose that when we are reading state we want to see all web server traffic except from source 1.2.3.4
Simple match-action rules don't allow us to express such exceptions.
The solution to this problem is a language primitive that allows us to express predicates, such as
(srcip !== 1.2.3.4) && (srcport == 80)A runtime system can then translate these predicates into low-level OpenFlow rules, ensuring that they are installed atomically and in the right order.
Unfolding Rules
Another problem that arises is that switches only have limited space for rules. It's simply not possible to install all possible rule patterns for every set of flows that we'd like to monitor.
For example, if we'd like to count the number of bytes for every source IP address and generate a histogram of the resulting traffic, we would potentially need a flow table entry for every possible source IP address.
The solution is to have the runtime system dynamically unfold rules as traffic arrives.
The programmer would specify something like a GroupBy(scrip) and the runtime system would dynamically add OpenFlow rules to the switch as traffic arrives.
This guarantees that there are only rules in the switch that correspond to active traffic.
Reading Network State
Another problem that arises when reading state is that extra unexpected events may introduce inconsistencies.
A common programming idiom is that the first packet goes to the controller, and once the controller figures out what policy to apply to that flow, the controller installs rules in the switches in the network corresponding to that flow.
Subsequent packets should not be sent to the controller, but what if more packets arrive before a rule is installed?
Multiple packets may reach the controller, but the application that is running on top of the controller may not need or want to see these packets.
The solution is to have the programmer specify via a high-level language something like Limit(1).
This could be used to indicate that the application should only see the first packet of the flow, and that the subsequent packets should be suppressed by the runtime system.
Writing Network Policy
There are many reasons that a controller might want to write policy to change the state in the network switches, including
- maintenance
- unexpected failure
- traffic engineering
Any of these network tasks require updating state in the network switches. When that state transition happens, we want to make sure that forwarding remains correct and consistent.
In particular, we'd like to maintain the following invariants
- no forwarding loops
- no black holes
- no intermittent security violations
Example of Inconsistent Write
Consider the following network, which is performing shortest path routing to some destination.
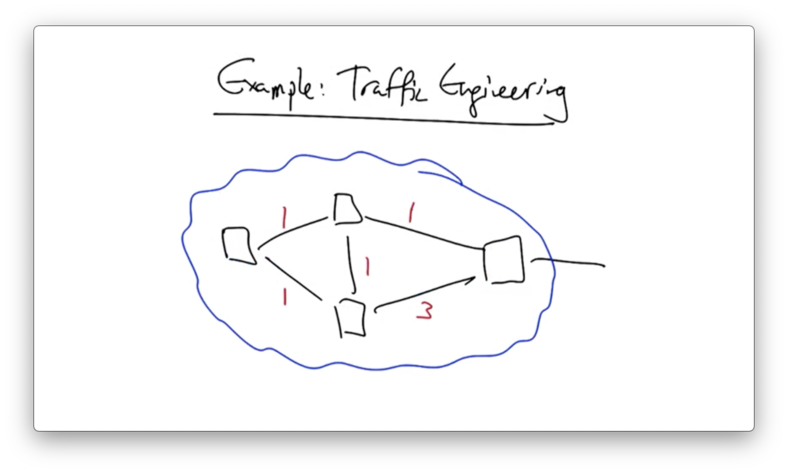
Traffic in the network would flow along the following path.
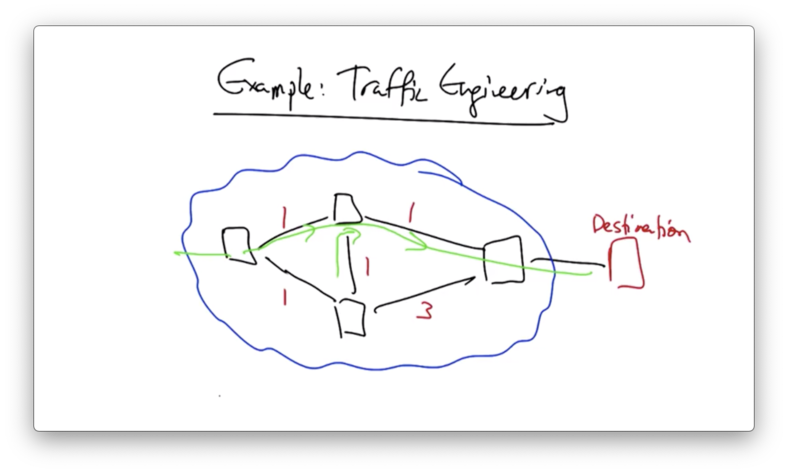
Suppose an operator wants to change the network state to shift traffic off of one link. This can be accomplished by adjusting the link weight.
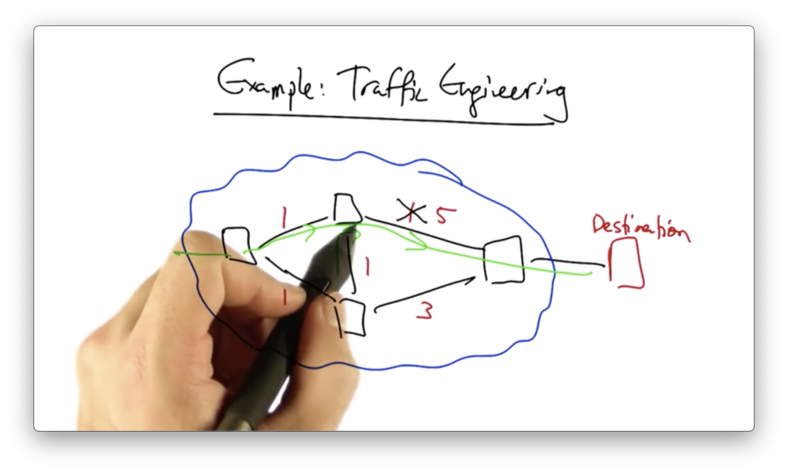
In doing so, the new shortest path is adjusted.
What if the state change in the top switch occurred before the state in the bottom switch could be updated?
In this case, we would have a potential forwarding loop.
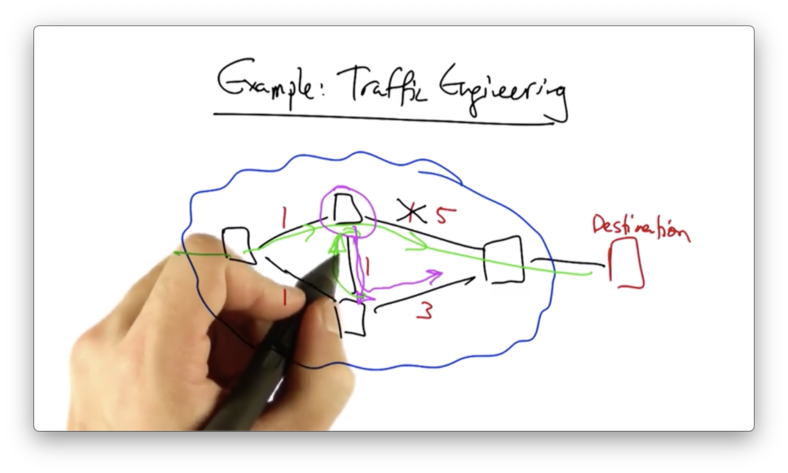
The top switch - with the new state - would forward to the bottom switch, and that switch - with the old state - would forward back to the top switch.
If rules are installed along a path out of order, packets may reach a switch before the new rules arrive. Therefore, we need atomic updates for the entire configuration.
Two-Phase Commit
The solution to this problem is to use a two-phase commit, such that packets are either subjected to the old configuration on all switches or the new configuration on all switches.
For this to work, packets must not subjected to the new policy on some switches and the old policy on other switches.
Assume we are trying to update from policy p1 to policy p2.
While the controller is updating the policy across switches, the incoming packets will be tagged with p1, which will signify that incoming packets will be using p1.
When all switches have received rules corresponding to p2, incoming packets can start being tagged with p2.
After some time, when we are sure that no more packets tagged with p1 are being forward through the network, we can then remove the rules corresponding to p1.
The naive version of two-phase commit requires maintaining both policies on all switches at once, essentially doubling the rule space requirements.
We can limit the scope of the two-phase commit by only applying this mechanism on switches that involve the affected portions of the topology.
Network Virtualization
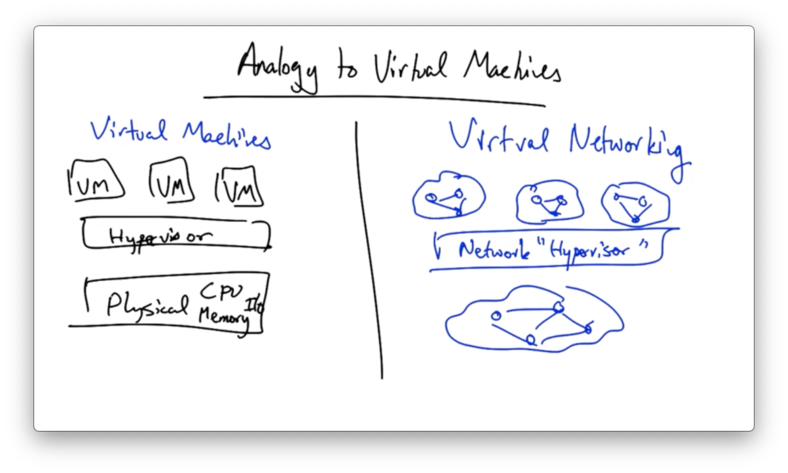
Network virtualization is an abstraction of the physical network where multiple logical networks can be run on the same underlying physical substrate.
For example, a logical network might map a particular network topology onto the underlying physical topology, and there may be multiple logical networks that map onto the same physical topology.
These logical networks might share nodes and links in the underlying topology, but each logical network has its own view as if it were running its own private version of the network.
The nodes in the physical network need to be shared. The nodes in the physical topology might be virtual machines.
Similarly, a single link in the logical topology might map to multiple links in the physical topology.
The mechanism to achieve these virtual links is typically via tunneling.
A packet destined from A to B in the logical topology might be encapsulated in a packet that is destined for some intermediate physical node X first before the packet is decapsulated and ultimately sent to B.
Analogy to Virtual Machines
Why Use Network Virtualization?
One of the main motivations for the rise of virtual networking was the ossification of the internet architecture.
In particular, because the internet protocol was so pervasive, making fundamental changes to the way the underlying internet architecture operated became increasingly difficult.
There was a lot of work on overlay networks in the early 2000s, but "one size fits all" network architectures were very difficult to deploy.
Rather than trying to replace existing network architectures, network virtualization was intended to allow for easier evolution.
Network virtualization enables evolution by letting multiple virtualized architectures exist in parallel.
In practice, network virtualization has really taken off in multi-tenant data centers, where there may be multiple applications running on a shared cluster of servers.
Well-known examples of multi-tenant data centers include Amazon's EC2, Rackspace and Google App Engine.
Large service providers such as Google and Yahoo also use network virtualization to adjust the resources devoted to any given service at any particular time.
Network Virtualization Uses SDN
There are several promised benefits of network virtualization.
One of the benefits is rapid innovation, since innovation can proceed at the rate at which software evolves, rather than on hardware development cycles.
Other benefits include allowing for new forms of network control and potentially simplifying programming.
Network Virtualization vs SDN
Network Virtualization is one of the first killer applications for SDN and SDN can be seen as a tool for implementing network virtualization, but the two are not the same.
The defining tenet of SDN is the separation of the data and control planes, whereas the defining tenet of network virtualization to separate the underlying physical network from the logical networks that lie on top of it.
SDN can be used to simplify many aspects of network virtualization, but it does not inherently abstract the details of the underlying physical network.
Design Goals for Network Virtualization
Virtual networks should be flexible. They should be able to support different topologies, routing and forwarding architectures, and independent configurations.
They should be manageable. They should separate the policy that the network operator is trying to specify from the mechanisms of how those policies are implemented.
They should be scalable - maximizing the number of coexisting virtual networks.
They should be secure: isolating the different logical networks from one another.
They should be programmable.
They should be heterogenous in the sense that they should support different technologies.
Nodes and Edges
Virtual networks have two components: nodes and edges.
The physical nodes themselves must be virtualized, and a popular strategy for virtualization is to use a VM or virtual environment.
The hypervisor - or whatever is managing the virtual environment - can effectively slice the underlying physical hardware to provide the illusion of multiple guest nodes.
Examples of node virtualization include
In a virtual network, we need to connect these virtual machines.
Often, we want to provide the appearance that these nodes are connected over a layer 2 topology even if they are actually separated by multiple IP hops.
We can achieve this by encapsulating the Ethernet packet in an IP packet. When the IP packet arrives at the destination, the host can decapsulate the IP packet and pass the original Ethernet packet to the VM residing on that physical node.
Each physical host may host multiple virtual environments, which creates the need for a virtual switch that resides on a physical host.
This virtual switch provides the function of networking virtual machines together over a virtual layer 2 topology.
The Linux bridge and Open vSwitch are examples of software switches that can provide this functionality.
Virtualization in Mininet
Mininet is an example of network virtualization, and allows us to run an entire virtual network on our laptop.
When we start Mininet with the mn command, each host in the virtual network is instantiated in a bash process with its own network namespace.
A network namespace is kind of like a VM, but much more lightweight.
The root namespace manages the communication between these distinct virtual nodes as well as the switch that connects these nodes in the topology that you create.
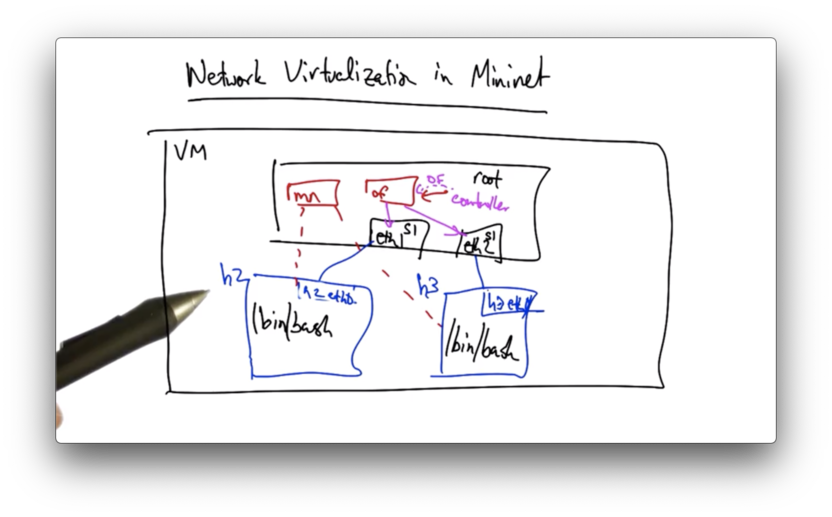
Virtual ethernet pairs are assigned to namespaces. For example, S1/Eth1 is assigned to an interface in h2's network namespace, and S1/Eth2 is assigned to an interface in h3's network namespace.
The OpenFlow switch performs forwarding between the interfaces in the root namespaces, but because the interfaces are paired, we get the illusion of sending traffic between h2 and h3.
When we make modifications to the OpenFlow switch via the controller, we are making changes in the root namespace.
SDN Programming Difficulty
Programming OpenFlow is not easy!
- very low level of abstraction in the form of match-action rules.
- controller only sees events that switches don't know how to handle.
- race conditions if switch-level rules are not installed properly.
SDN Programming Interface
A northbound API is a programming interface that allows applications and other orchestration systems to program the network.
At the low level we have the controller updating state in the switch using OpenFlow flow modification rules. The communication interface between the controller and the OpenFlow switch is referred to as the southbound API.
We may have applications that need to perform more sophisticated tasks like path computation or loop avoidance, which cannot really be expressed through the southbound API.
We need a higher-level programming interface that allows applications to talk to the controller so that an application is not writing low-level OpenFlow rules, but rather is expressing what it wants to have happen in terms of higher-level semantics.
Various people may write these applications, such as network operators, service providers and researchers.
The benefits of the northbound API include vendor independence and the ability to quickly modify/customize controllers via various popular programming languages.
Examples of applications that may leverage northbound APIs include large virtual switch implementations, security applications and middle box integration services.
Currently, there is no standard for the northbound API like there is for the southbound API with OpenFlow.
Frenetic Language
One example of a programming language that sits on top of the northbound API is frenetic, a SQL-like query language.

In this example, frenetic is being used to count the number of bytes coming in on port 80, grouped by destination MAC address, with the updates to the counters being reported every 60 seconds.
Overlapping Network Policies
One issue with programming at this high level of abstraction is that an operator might write multiple modules, each of which affects the same traffic.
Ultimately, all of the modules need to be combined into a single set of OpenFlow rules that together achieve the network operator's overall goal.
In order to do this, we need composition operators; that is, ways to specify how individual modules should be combined into a single coherent application.
Composing Network Policies with Pyretic
One way of composing policies is to perform both operations simultaneously.
For example, we might want to forward traffic and also count how much traffic is being forwarded. Those operations can be performed in parallel.
We can also compose policies sequentially, whereby one operation is performed before the next.
For example, we may want to implement a firewall and then switch any traffic that makes it past the firewall.
One example of sequential composition might be load balancer routing.
A policy might take some traffic coming from half of the source IP address and rewrite the destination IP address to point to one server replica, and take the other half of the traffic and rewrite the destination IP address to point to the other server replica.
After the load balancer rewrites the destination IP addresses, we need a routing module to forward the traffic out the appropriate port on the switch.
In this case we have a sequential composition of a destination IP address rewrite followed by a forwarding operation.
The ability to compose policies in this fashion allows each module to partially specify functionality without having to write the policy for the entire network.
This leaves some flexibility so one module can implement a small bit of the network function, leaving some functions for other modules.
This also leads to module reuse, since a module need not be tied to a particular network setting.
For example, the load balancer described above spreads traffic across the replicas without regard to the underlying network paths that that traffic takes once those destination IP addresses are rewritten.
Pyretic Language
Pyretic is an SDN language and runtime. The language provides a means of expressing high-level policies, and the runtime compiles these policies to the OpenFlow rules that are installed on the switches.
One key abstraction in pyretic is located packets. With located packets, we can apply a policy based on a packet and its location in the network, such as the switch on which that packet is located or the port on which that packet arrives.
Pyretic supports the implementation of network policy as a function: receiving a packet as input and returning zero, one, or multiple - potentially modified - packets as output.
Another feature of pyretic is the notion of boolean predicates. Unlike OpenFlow rules, which do not permit the use of simple conjunctions, like and or or, or negations, like not, Pyretic allows the expression of policies in terms of these predicates.
Pyretic also provides the notion of virtual packet header fields, which allows the programmer to refer to packet locations and also to tag packets with arbitrary metadata that can be read by subsequent functions.
Pyretic also provides composition operators, such as those used for parallel and sequential composition.
The notion of network policy as a function contrasts with the OpenFlow style of programming. In OpenFlow, policies are simply bit patterns: match statements for which matching packets are subject to a particular action.
In contrast, in Pyretic policies are functions that map packets to other packets.
The identity function returns the original packet. The drop function returns the empty set. The match(f=v) function returns the identity if the field f matches the value v; otherwise, drops the packet. The mod(f=v) function returns the same packet with the field f set to v. The fwd(a) function is syntactic sugar around mod(outport=a). The flood function returns one packet for each port on the network spanning tree.
In Pyretic, the packet is nothing more than a dictionary that maps a field name, such as the destination IP address, to a value, such as 1.0.0.3.
The field names can correspond to fields in an actual packet header, but they can also be virtual.
Using a dictionary to represent the packet allows for easy injection of virtual header header fields and presents a unified format for representing packet metadata.
Composing Network Policies with Pyretic II
Pyretic enables the notion of both parallel and sequential composition.
match(dstIP=2.2.2.8) >> fwd(1)demonstrates sequential composition, represented by the >> operator.
Parallel composition allows two policies to be applied in parallel, with the + operator.
match(dstIP=2.2.2.8) >> fwd(1) + match(dstIP=2.2.2.9) >> fwd(2)In this example, we are applying two policies in parallel: one that forwards packets destined for 2.2.2.8 on port 1, and one that forwards packets destined for 2.2.2.9 on port 2.
Pyretic also allows an operator to construct queries that allow the program to see packet streams.
self.query = packets(1, ['srcmac', 'switch'])In this example, the operator uses the packets function to see packets arriving at a particular switch with a particular source MAC address.
The argument 1 indicates that we only want to see the first packet that arrives with a unique source MAC address and switch.
We can register callbacks for these packets streams that are invoked to handle each new packet that arrives for that query.
self.query.register_callback(learn_new_mac)
Dynamic Policies in Pyretic
Dynamic policies are policies whose forwarding behavior can change.
They are represented as a time series of static policies, and the current value of the policy at any time is self.policy.
A common programming idiom in Pyretic is to set a default policy and then register a callback that updates that policy.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy