Information Security
Authentication
16 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Authentication
What is Authentication?
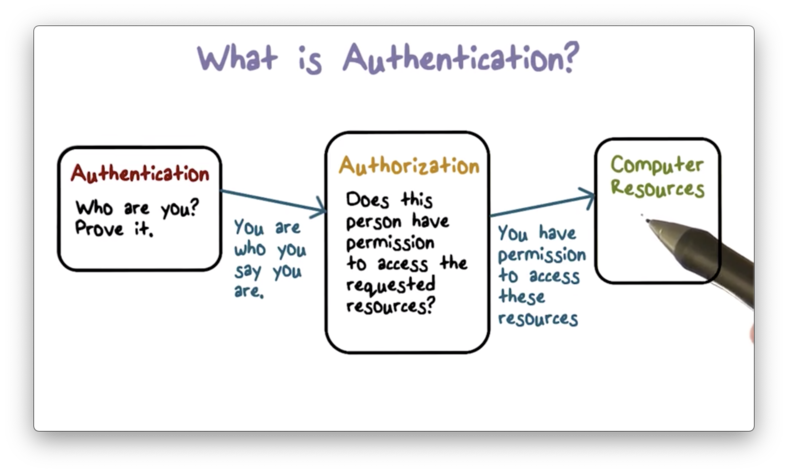
We can understand the importance of authentication by going back to the conversation about trusted computing bases.
We have resources that need to be protected, and we can achieve this protection by using a trusted computing base that serves as a reference monitor.
Every request for every resource must be monitored, and the trusted computing base has to determine whether to accept or deny each request.
In order to make this decision, the TCB has to know the source of such requests, and authentication is the mechanism by which these sources are identified.
The first step in authentication is identification. Of course, a requestor cannot just claim whatever identity they'd like. As a result, the second step in authentication is identity verification.
For a concrete example, we identify ourselves when we supply our username to a login form, and we verify that identity when we supply our (secret) password.
Once we establish the source of a request, the next step is authorization. In authorization, the operating system decides whether the source of the request has the permission to access the resource they are requesting.
Once authentication and authorization are complete, then the operating system can allow access to the protected hardware resources.
The operating system needs to know who is making a request for a protected resource.
In a computer system, a request comes from a process, and each process runs on behalf of a certain user (also referred to as a subject or principal) within that computer system.
Therefore, authentication helps us answer the question: on whose behalf is the requesting process running?
We can answer this question with authentication. Before a user is allowed to interact with a computer system, they must first authenticate themselves - by logging in, for example.
Once authenticated, the OS is able to link any subsequent process or application resource requests back to the authenticated user.
Authentication Goals
When a legitimate user tries to authenticate herself, the system can demand some evidence, but when the right evidence is provided the system should allow the login to complete successfully.
This is called availability. The system is available to the user who is able to provide the sufficient evidence to support their claim to their identity.
In other words, we don't want to have any false negatives. This means that we don't want to have the situation where we deny access to a user who has provided sufficient evidence that they are who they claim to be.
On the other hand, we don't want to have a system that allows a malicious user to successfully impersonate a valid user.
In other words, we don't want to have any false positives. This means that we don't want to have a situation where we grant access to someone who is not who they claim to be.
Authentication systems that have low false positive rates are said to have authenticity. That is, these systems ensure that they only authenticate users with authentic claims to their identity.
Authentication Quiz

Authentication Quiz Solution

If someone steals your phone, you will be thankful for your lock screen/passcode.
How is Authentication Implemented?
There are three basic methods for implementing authentication.
Authentication can be implemented using something a user knows. This could be a secret shared by the user and the operating system - a password, for example. The fact that a user is able to produce this secret during authentication is evidence that they are who they claim to be.
Authentication can also be implemented using something that the user has. For example, possession of a token or a smart card may be sufficient as a means of identity verification for some systems.
Finally, authentication can be implemented using something that the user is. For example, a system may be able to authenticate a user by digitizing and processing his or her fingerprint or voice. Such biometric data must be unique to each user for this scheme to be useful.
Here is a diagram illustrating the basic steps in an authentication interaction between as user and a system.
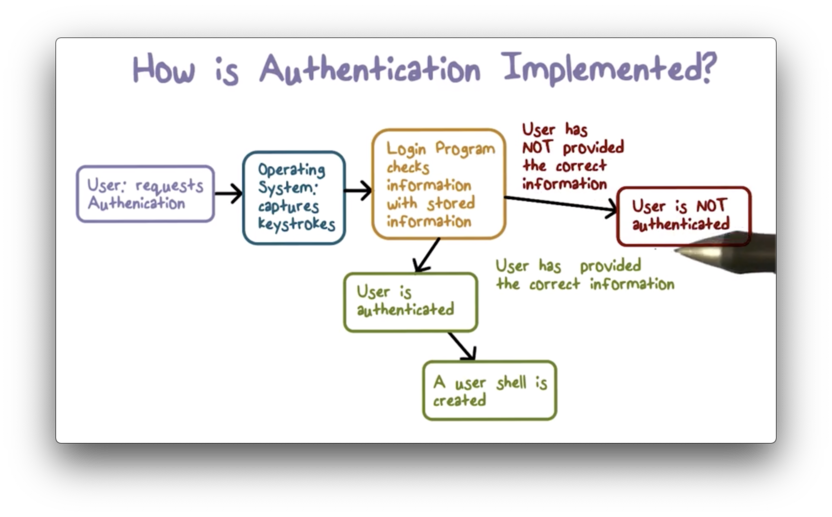
The user first comes to the system and requests access to it. In this request they claim an identity and provide a means of verifying that identity.
The operating system can take the supplied authentication information check it against stored information for the claimed identity.
If there is a match between what the system knows and what a user provides, then the user is authenticated, and a user shell is created.
If the check fails, then the system believes that the user has not provided the correct information. If so, the identity being claimed probably doesn't belong to the user who is asking for authentication.
In this case, the system doesn't have the right match and authentication fails.
Login Attacks Quiz

Login Attacks Quiz Solution

Remember, the positive event is gaining access to the system. A false positive is gaining access erroneously. An attacker authenticating as someone else is a false positive.
Implementation Quiz

Implementation Quiz Solution

Threat Modeling of the Password Method
How can we attack password-based authentication?
A password is a secret shared between a legitimate user and the system, but that doesn't mean an attacker can't try to guess it. As obvious as it may seem, using common or weak passwords presents a real vulnerability in authentication systems.
When you authenticate with a computer system, how do you know that you are really talking to the system instead of a program that is impersonating the system? A hacker can create a fake login program and then steal your credentials as you type them in.
Finally, an attacker may install malicious software called a keylogger onto your machine, which will record all of the keyboard keys that you press. Keyloggers can be used to steal your password without have to impersonate the login program.
Importance of a Trusted Path
When using a trusted path, a user can have confidence that there is no application between the user and the operating system.
The hardware and the operating system work in tandem to provide a trusted path.
For example, to login to windows systems you have to press the key sequence CTRL-ALT-DEL. This sequence can't be trapped by any other program besides the operating system. Thus, you can be confident that you are communicating directly with the operating system after pressing this sequence.
In addition, the display and keyboard must be connected to the CPU on which the operating system is running, in a way in which there is no one in between. As I/O devices, they need to be using their own trusted path to the OS.
Sometimes, visual feedback can be provided to assure the user that they are using the trusted path, such as a certain type of display on a computer monitor or a light on a keyboard.
Password Popularity Quiz

Password Popularity Quiz Solution

If we are attacking systems, we might get the best bang for our buck trying these passwords.
Implementing Password Authentication
When a user authenticates with a computer system, they must supply their identity and some verification of that identity. In password-based systems, this verification is the user's password.
When a user supplies their password to a computer system, the system then has the task of verifying that this is the correct password for this user.
How does the system know the user's password? One solution is to ask users to share their password with the system when they create their account. This is known as enrollment.
After enrollment, how does the system store the password?
Method 1
The system can persist user passwords in plaintext in a system file. All the system has to do is compare the supplied password against the stored password.
As a basic security measure, the file should only be readable by the root/admin user, which is the user on whose behalf the login program runs.
What if permissions are set incorrectly? If so, someone else may be able to read that file and learn everyone's password.
Even if the permissions are set correctly, why should the admin know the passwords? If an attacker can impersonate the root user, they can learn all the passwords.
It's clear that something about the secret has to be shared with the system, but storing those secrets in a file as plaintext - even with access control - is not a good idea.
Method 2
Alternatively, the system don't store the passwords themselves, but rather stores something derived from them.
We can pass the password through a one-way hash function to create this derived value.
Hash functions are often used to take an arbitrary length input and produce a fixed-size output that is fairly unique to the input.
A one-way hash function means that it is easy to compute the hash value given the input, but it is very difficult to recreate the input given the hashed value.
During enrollment, the system applies the hash function to the supplied password and writes this value to the file. When a user later comes to authenticate, the system hashes the supplied password and checks that value against the persisted hash value.
The benefit of this approach is that if an attacker steals this file they cannot compromise any user accounts because they can't recreate the original passwords.
Even so, these password files should still only be readable by the root user.
Hash Functions
A hash function takes a variable length password and outputs a fixed-length hash value.
A hash function is a one-way function, which means that it is very difficult to invert. In other words, it's easy to compute a hash given an input, but it's very difficult to recreate an input given a hash.
Hash Functions and Threats
We assume that the one-way property of hash functions holds, so hash function inversion is not a threat.
One vulnerability present in authentication systems that use hash functions is users using common passwords.
Since the hash functions being used are well-known (remember security by obscurity is not a thing), an attacker can easily compute the hash of well-known password values.
If the attacker can get ahold of the system password file, they can hash common passwords and check the hashes against the file.
For example, if the password file contains the hash value 'abcdef' for Bob's account, and the attacker determine that passing '123456' through the hash function yields 'abcdef', then the attacker knows that Bob's password is '123456'.
In a dictionary attack, a malicious user passes a large dictionary of common passwords - with some common mutations - to a series of hash functions in order to match against a stolen password file.
Dictionary attacks are examples of an offline attack, whereby the malicious user is not interacting directly with the system. When the user interacts with the system - a so-called online attack - the system can block subsequent login attempts after some number of failed attempts.
In offline attacks, the attacker has plenty of time to test a wide value of common passwords and hash functions against a stolen password file.
Password Quiz

Password Quiz Solution

A trusted path ensures that there is no application between the user and the operating system. Without this path, malicious programs may intercept login credentials.
Hashed Passwords Quiz

Hashed Passwords Quiz Solution

Hash Function Characteristics Quiz

Hash Function Characteristics Quiz Solution

Brute Force Guessing of Passwords
If an attacker has a system password file, how hard is it for them to brute force hash every single possible password?
There is publicly available software that can compute 10^8 MD5 hashes per second using a graphical processing unit, a piece of hardware which is particularly well-suited for performed hashing calculations.
If the password is only six random alphanumeric characters (A-Z, a-z, 0-9), then the space of possible passwords is 62^6. There are 62 (26 + 26 + 10) possible characters for each position in the password, and there are 6 positions.
Using the above software, it will take 62^6 / 10^8 seconds - about ten minutes - to compute hashes for all possible passwords in that space.
If we increase the size of the password to eight random characters, the space grows from 62^6 to 62^8, increasing the computation time from ten minutes to about twenty-five days.
Regardless, this is not an unfeasible amount of time for a hacker to wait while a program exhaustively searches a password space.
As a fun aside: increasing the password length to nine random characters increases the search time to 4.29 years, and increasing it to ten random characters increases the search time to 266 years.
Passwords are not Really Random
Passwords are not really random, so when an attacker is trying a brute force attack, they don't have to search for things in a completely random manner.
A smart attacker will try popular passwords first - for example, "password" and "123456" - in order to reduce the amount of work that they have to do.
An attacker can create a rainbow table mapping potential passwords to their hash values. With this table, the attacker doesn't even need to perform the hashing directly. Instead they can just lookup hash values from the password file and see what password maps to those hash values.
What if two users pick the same password? This is not an unlikely occurrence, given the popularity of a relatively small set of common passwords.
If multiple users use the same password, the hash values will be equal. This means that if an attacker compromises one of these accounts, they instantly compromise all of them.
To avoid this situation, we can add a salt - a random number - to each password before we hash it. Since the salt is randomly selected during enrollment, the salt and therefore the hash for users with the same password will be different.
Since the hashed value is derived from the salt and the password, the salt must be stored in the password file with the hashed value.
Brute Force Figure
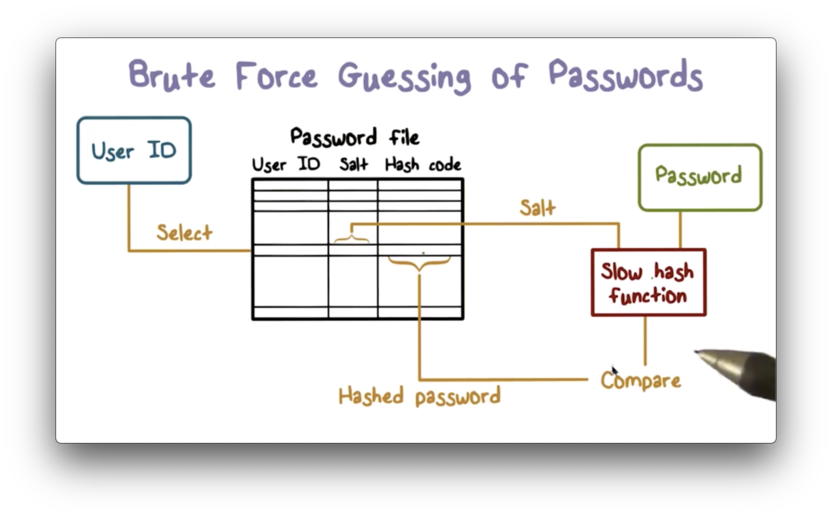
An enrolled user attempts to authenticate with the system by supplying a user id and a password.
The system indexes into the password file using the supplied user id in order to get the correct entry. This entry contains the user id, the salt, and the hash value.
The system then takes the supplied password, and the saved salt, and runs them both through the hash function. If the resulting hash value matches the hash value in the entry then access to the system is granted.
It is important to note that the hash function used by the system is intentionally slow. This is done to ensure that brute force attacks take much longer.
Unique PINS Quiz
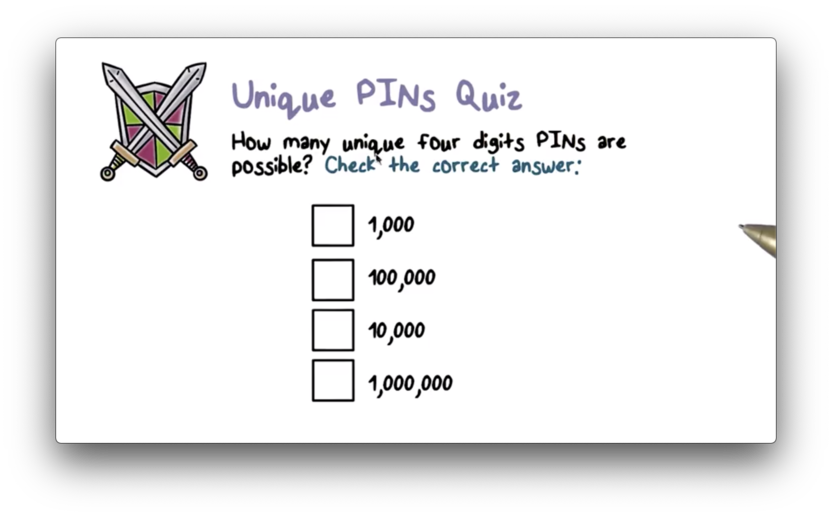
Unique PINS Quiz Solution
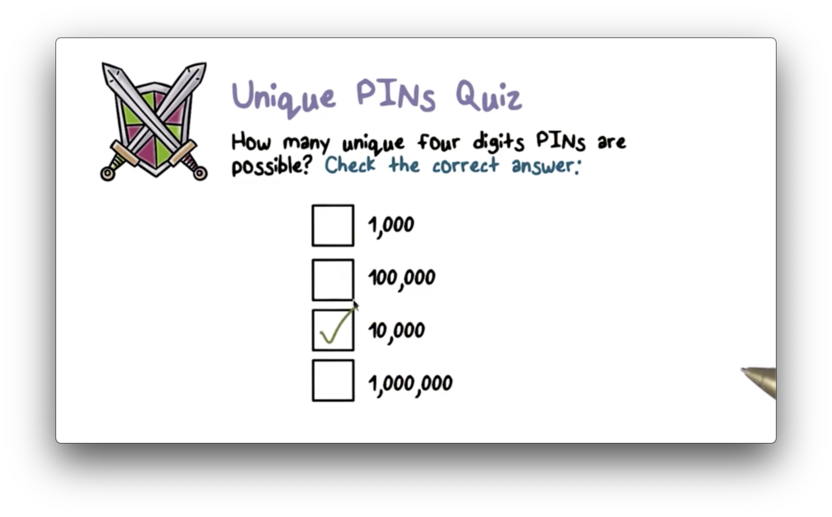
With ten options for the first digit, ten options for the second digit, and so on, the total number of four digit pins is 10 10 10 * 10, or 10^4, or 10,000.
Brute Force Quiz

Brute Force Quiz Solution

With 72 options for each other six characters, the total number of unique passwords is 72^6, which is the number of attempts the hacker will have to make in the very worst case.
Touch Screen Passwords Quiz

Touch Screen Passwords Quiz Solution

Basically, the idea here is that attackers will likely not have to exhaustively search the space of possible patterns because biases exist that greatly shrink this space into a much smaller space of much more probable patterns.
Problems with Passwords
Although we use passwords all the time, there are plenty of problems with passwords.
For passwords to be strong - that is, harder to crack - they need to be long and complex. This increases the size of the space that attackers need to search, but it also increases the complexity for users, at the expense of usability.
Even with strong passwords, there are problems that are related to the trusted path. When a system asks you to authenticate yourself, how do you know the system is not being impersonated? Phishing and social engineering attacks arise from users not authenticating the entities trying to authenticate them.
Unfortunately, once a password is stolen, it can be used many times because a password grants continual access. We can address this by having polices that enforce frequent password change, but again this hurts usability.
Finally, humans have a hard time remembering many different passwords for all of the different accounts they may have. As a result, people will often choose simple passwords that are easy to remember - and guess - and reuse these passwords across accounts.
Best Practices for System Administrators
Never store plaintext passwords. Instead, store only hashed values generated with a random salt and limit access to password file where the hash value is stored.
Use a slow hash function. They system has to execute this function only once when the user logs in, so speed is not crucial for this use case.
On the other hand, someone running a brute force attack will execute the function again and again, and a slow hash function will slow their attack down.
Best Practices for Users
Use a password manager to generate and maintain complex passwords for the services you use. Make sure to use a strong password for the password manager itself.
Something You Have Authentication
Since passwords have problems, we can look at other authentication strategies.
We can authenticate users based on something they have - such as a smart card or a token - instead of using something they know, like a password.
How is authentication implemented with a smart card?
Often, the authentication flow will include a challenge-response. In challenge-response the system may send some sequence of characters to the token, and the token will send back a response based on this challenge. This response can be the same sequence encrypted with the token's private key, for example.
Thus, the system can authenticate the smart card and, by proxy, the user in possession of the smart card.
One obvious ramification of this approach is that the users must be in physical possession of the smart card in order to authenticate. If you leave your smart card at home, you'll have to go back at get it.
In addition, a smart card needs special hardware - such as a card reader - installed in order to communicate with the system. This added requirement adds cost to the implementation of this type of authentication system.
Another problem with this approach is misplaced trust. For example, the RSA SecureID system breach created a situation in which tokens could potentially be forged by attackers.
Something You Are Authentication
Finally, authentication can be based on biometrics or, more colloquially, "something you are".
For example, a system can look at the pattern of ridges and grooves in a supplied fingerprint to verify a user's identity.
Alternatively, a system can analyze keystroke dynamics, such as how fast a user types or how long it takes a user to transition from certain keys to others. This data can be synthesized to create a representation of a specific user.
(To be fair, keystroke dynamics fall more into the "something you do" category, as opposed to the "something you are" category. Such behavioral identifiers are sometimes referred to as behaviometrics.)
Some systems can analyze the sound and speed of your speech to authenticate you by your voice. Other systems can verify your identity by scanning your retina and measuring the underlying blood flow.
There are many different choices for biometrics, but they should all be unique to an individual. A feature that many people share - such as height in inches - is not a sufficient biometric for the purpose of authentication.
In addition, the biometric recording should be the same during each authentication attempt. Otherwise, the system may deny you access: a false negative.
Of course, this consistency is not always possible. For example, a cold can impact your voice and moisture or swelling can obscure your fingerprint.
Instead of looking for exact measurements when using biometrics, a system might use a probability distribution when verifying identity.
The system will have to pick a certain threshold of similarity by which the false negative rate and the false positive rate are balanced appropriately.
False negatives - denying valid users access - hurts usability while false positives - allowing Alice to authenticate as Bob - is insecure.
Implementing Biometric Authentication
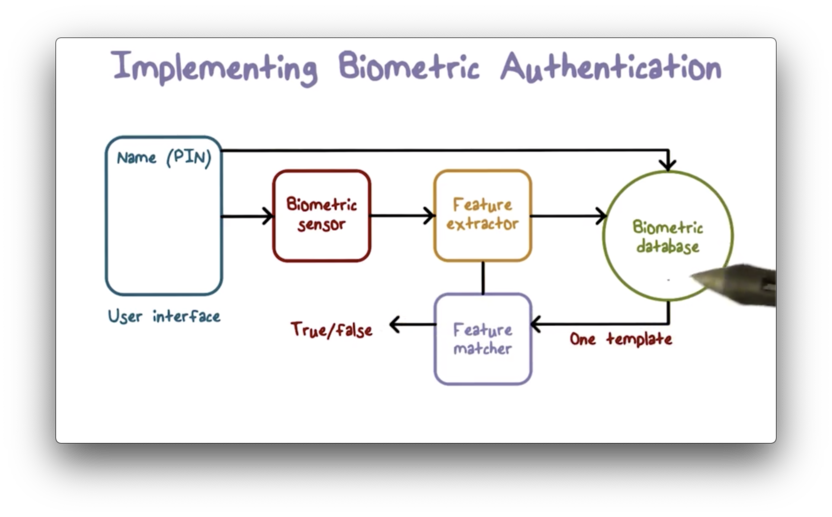
After a user supplies their identity to a system, the biometric sensors capture the biometric data of interest.
The system then digitizes this data and extracts certain key features to be used for matching.
The extracted features - or some data derived from them - are matched against the stored data for the given user and, if there is a match, the system grants access to the user.
Other Methods
Multi-factor Authentication
We can combine different factors (something you know, something you have, something you are) into a multi-factor authentication strategy.
For example, some websites may require you to log-in with your password and then ask you to enter a code that they text to you. The password is something you know, and the code is something you know based on something you have.
Another example is the ATM card and PIN combination required to withdraw money from the bank. The card is something you have and the PIN is something you know.
Other authentication methods can incorporate other factors. For example, a system can use a location-based factor - "somewhere you are" - by examining IP addresses in network requests.
Multi-factor authentication makes it harder for attackers to impersonate users.
Authentication over a Network
When we are authenticating with services over the open Internet, we no longer have the trusted path to the OS authenticating us.
Cryptography helps secure network communication through encryption and shared secrets. Of course, this doesn't help against certain man-in-the-middle attacks.
Multi-factor Authentication Quiz

Multi-factor Authentication Quiz Solution

Remember, a false positive occurs when a malicious user is granted access to the system as a valid user. The likelihood of this happening decreases when multiple authentication components are employed by the system.
Chip and Pin Authentication Quiz
Chip and Pin Authentication Quiz Solution
Biometric Authentication Quiz

Biometric Authentication Quiz Solution

As a basic example, consider someone recording your voice and playing it back to a voice-based authentication system.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy