Machine Learning Trading
Dyna
5 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Dyna
Overview
One problem with Q-learning is that it takes many experience tuples to converge. Gathering experience from the real world is expensive because it requires us to take real action - executing a live trade in our case - to gather information.
To address this problem, researchers developed a technique called Dyna. Dyna works by building models of the transition function, , and reward function, . Then, after each real interaction with the world, we hallucinate many additional interactions, typically a few hundred, which we use to update the Q-table.
Dyna-Q Big Picture
Dyna-Q is an algorithm developed by Richard Sutton intended to speed up learning, or policy convergence, for Q-learning. Remember that Q-learning is a model-free method, meaning that it does not rely on, or even know, the transition function, , and the reward function, . Dyna-Q augments traditional Q-learning by incorporating estimations of both and , based on experience.
Let's quickly recap the Q-learning algorithm we've been using thus far. We first initialize our Q-table, and then we begin iterating. We observe a state, , execute an action, , after which we observe a new state, , and a reward, . Using this experience tuple, we update our Q-table. Finally, we repeat the process, continuously gaining experience from the world and improving our Q-table.
When we augment Q-learning with Dyna-Q, we add three new pieces. First, we add logic that enables us to build models of and . Then, for lack of a better term, we hallucinate a number of experiences. Finally, we update our Q-table according to the experience tuples we generated during the hallucination. We repeat these steps potentially several hundred times for each real experience.

When we talk about updating our model, what we want to do is find new values for and . Remember that is the probability that if we are in state and take action we will end up in state , while is our expected reward from taking action in state .
Before we talk about how we hallucinate an experience, it's essential to understand why we might want to do this in the first place. The issue is that interacting with the real world can be very expensive, in terms of time, money, or some other resource, while hallucinations are cheap. By hallucinating a large number of experiences - say 100 or 200 - for every real experience, we can amortize the cost of a real experience over many Q-table updates.
We can hallucinate an experience in two steps. First, we randomly select a state, , and an action, . Next, we infer the new state, , using , and we infer the reward, , using . Using this synthetic experience tuple, we can update our Q-table.

Learning T
Remember that represents the probability that if we are in state, , and we take action, , we end up in state, . To learn a model of , we need to observe and record the frequency with which state transitions occur.
We can introduce a new table, , of dimensions, , where is the number of total possible states, and is the number of total possible actions. We initialize the cells in to a very small number to avoid a potential divide-by-zero situation.
As we iterate through the Q-learning process, we accumulate experience tuples. For each , , and that we acquire, we increment the count in . In this fashion, we can record the frequency of state transitions, which serves as an empirical model of .
How to Evaluate T Quiz
Assume we have been interacting with the real world for a while, and we would like to consult our model of . Can you write an equation for in terms of ?
How to Evaluate T Quiz Solution
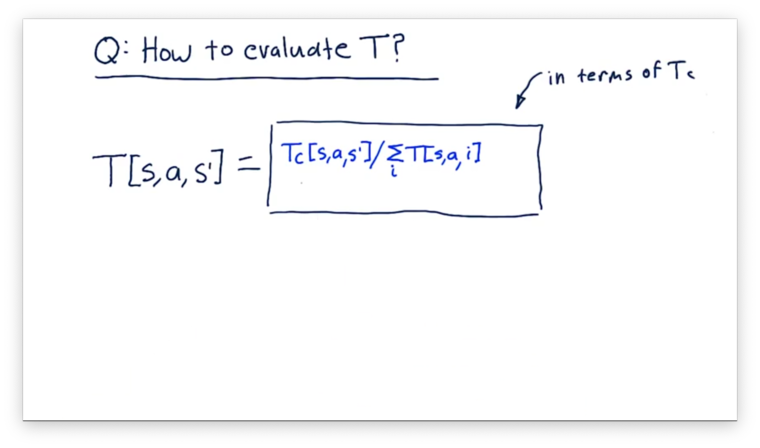
NOTE: The denominator in this equation should reference , not .
What we want to find here is the probability of a particular resulting state, , given a current state, and an action, . Thus, we need a fraction where the numerator is the number of transitions from to , by way of , and the denominator is the total number of transitions out of , by way of .
Let's consider the numerator first. The total number of transitions from to , as a result of , is simply the recorded value, .
Next, let's consider the denominator. The total number of times we transitioned out of by taking is the sum , where is the size of , the state space.
Altogether, we have the following equation:
Learning R
In addition to learning a model of , we also need to learn a model of . Remember that gives us the expected reward for taking an action, , from a state, . Recall also that each experience tuple contains an immediate reward, , for taking the corresponding action from the corresponding state.
Given this, we can formulate a simple equation for , which we update after each real experience. Notice that this update equation is very similar to the Q-table update equation, incorporating the same learning rate, , that we used in that equation.
Dyna-Q Recap

OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy